Today, we are excited to announce preview support for the LFM2-24B-A2B, the latest high-performance model from Liquid AI, across Intel® AI PC, edge devices, and data center platforms.
LFM2-24B-A2B scales the LFM2 hybrid architecture to its largest Mixture of Experts model yet. While the model contains 24B total parameters, its sparse architecture only activates 2.3B parameters at a time. These approaches make the model incredibly fast and hardware-aware, perfectly suited for the low-memory, high-throughput, and low-latency requirements of agentic applications. Liquid AI shared more details about the architecture, training approach, and performance benchmarks in their launch announcement blogs - Technical overview blog and their Intel partnership.
Where does this model shine? The LFM2-24B-A2B delivers exceptionally fast prefill and decode speeds at low memory cost. The model excels at instruction following, agentic workflows, and complex multi-step mathematical reasoning. The model is an ideal engine for agentic tool use for on-device assistant, offline document summarization and Q&A, multi-turn support conversations with tool access (database lookups, ticket creation), and RAG pipelines, all without data leaving the network.
OpenVINO™ support is critical for MoE models because only a subset of parameters (the “experts”) is active at any time. This sparsity is efficient but can be hard to optimize on general-purpose hardware. OpenVINO™ ensures CPU and GPU resources are fully leveraged, maximizing throughput and reducing latency, and enables these models to run efficiently on AI PCs with Intel® Core™ Ultra Series 3 processors. Combined with Liquid AI’s MoE architecture, developers can deploy powerful, capable models while keeping memory usage low, even for long-context tasks.
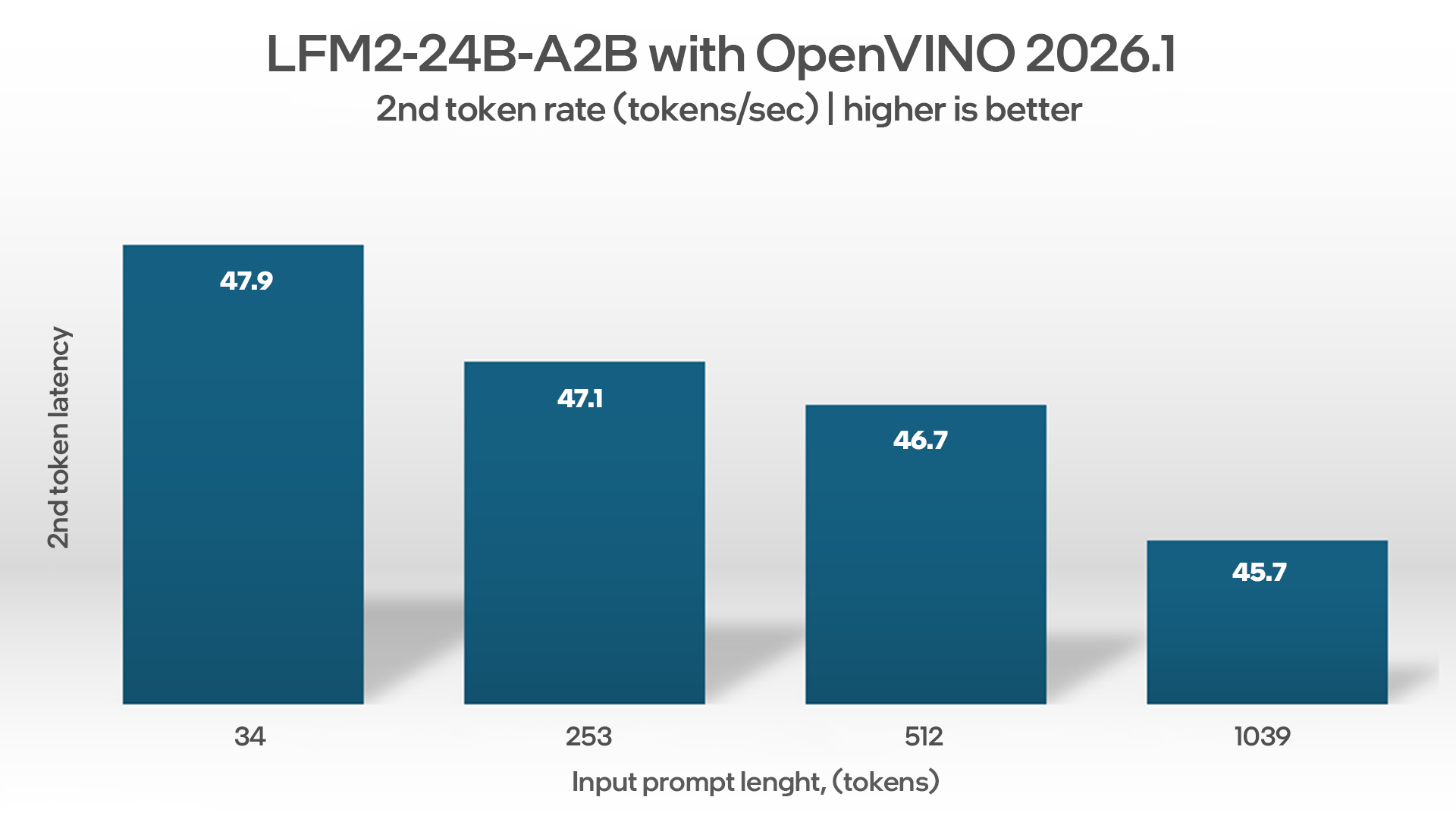
We benchmarked the inference latency of the LFM2-24B-A2B on an AI PC powered by Intel® Core™ Ultra X7 358H processor with a built-in Intel® Arc™ graphics using the OpenVINO™ toolkit for performance optimization. OpenVINO helps accelerate AI inference while enabling improved throughput and accuracy.
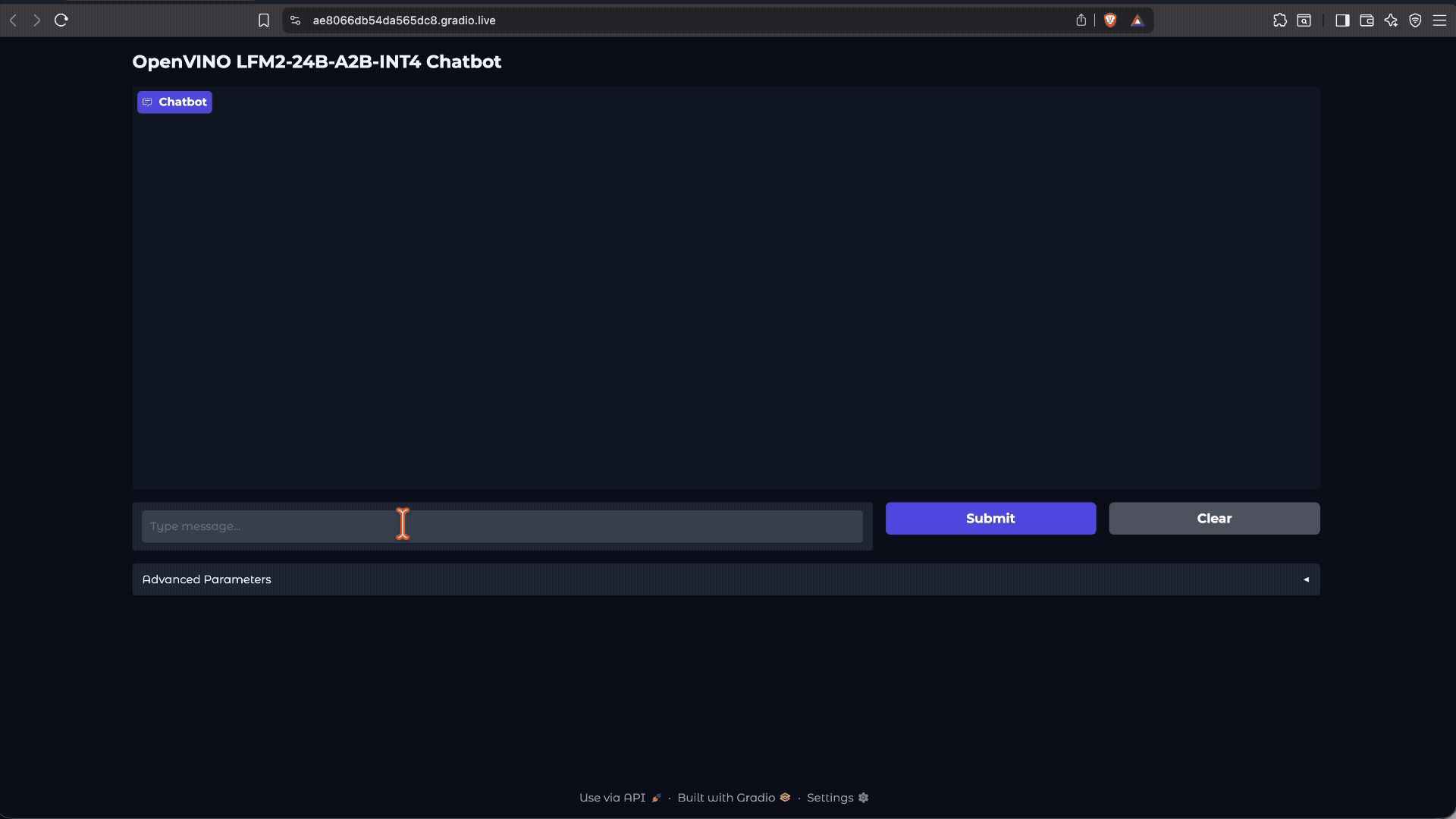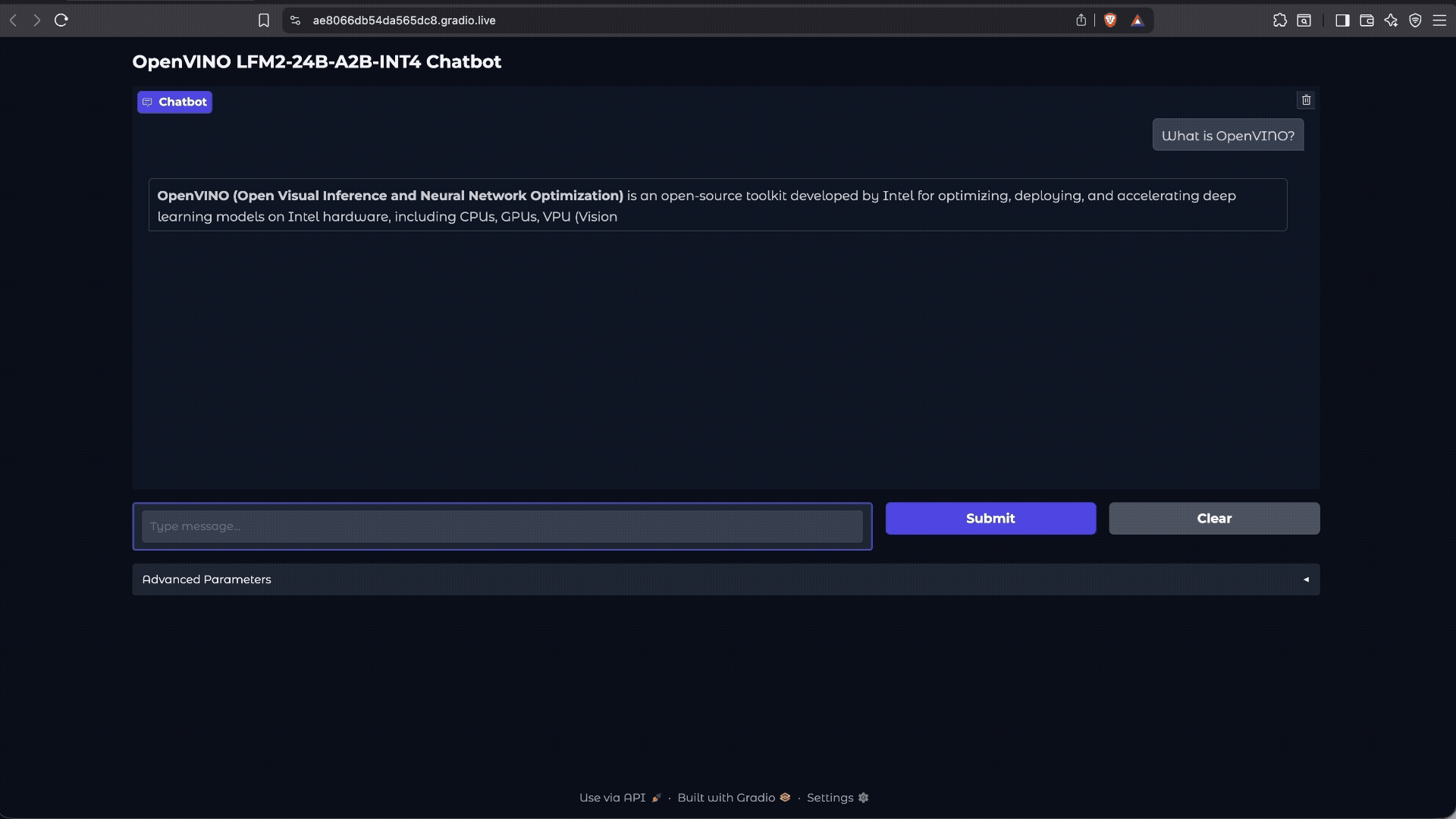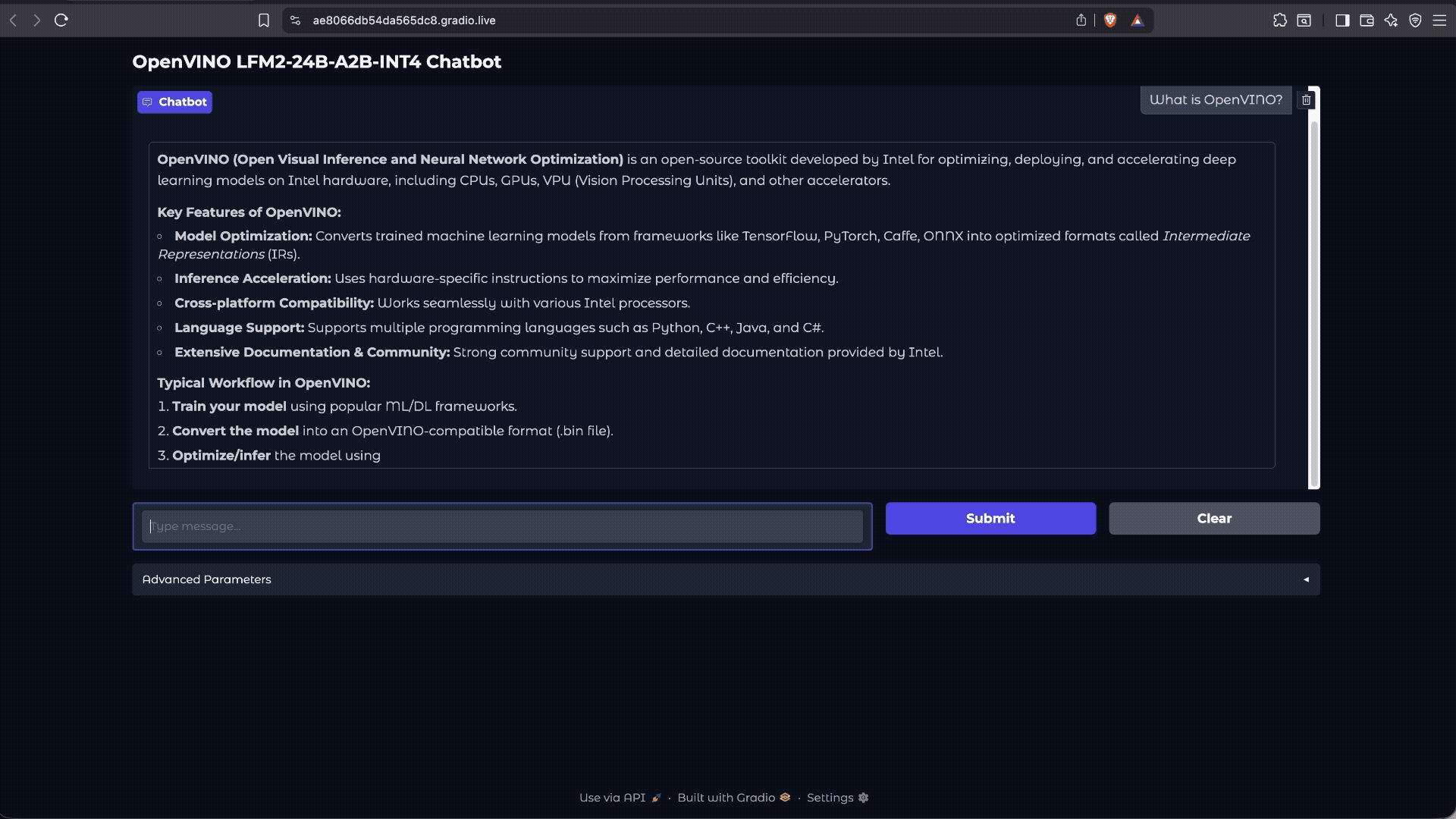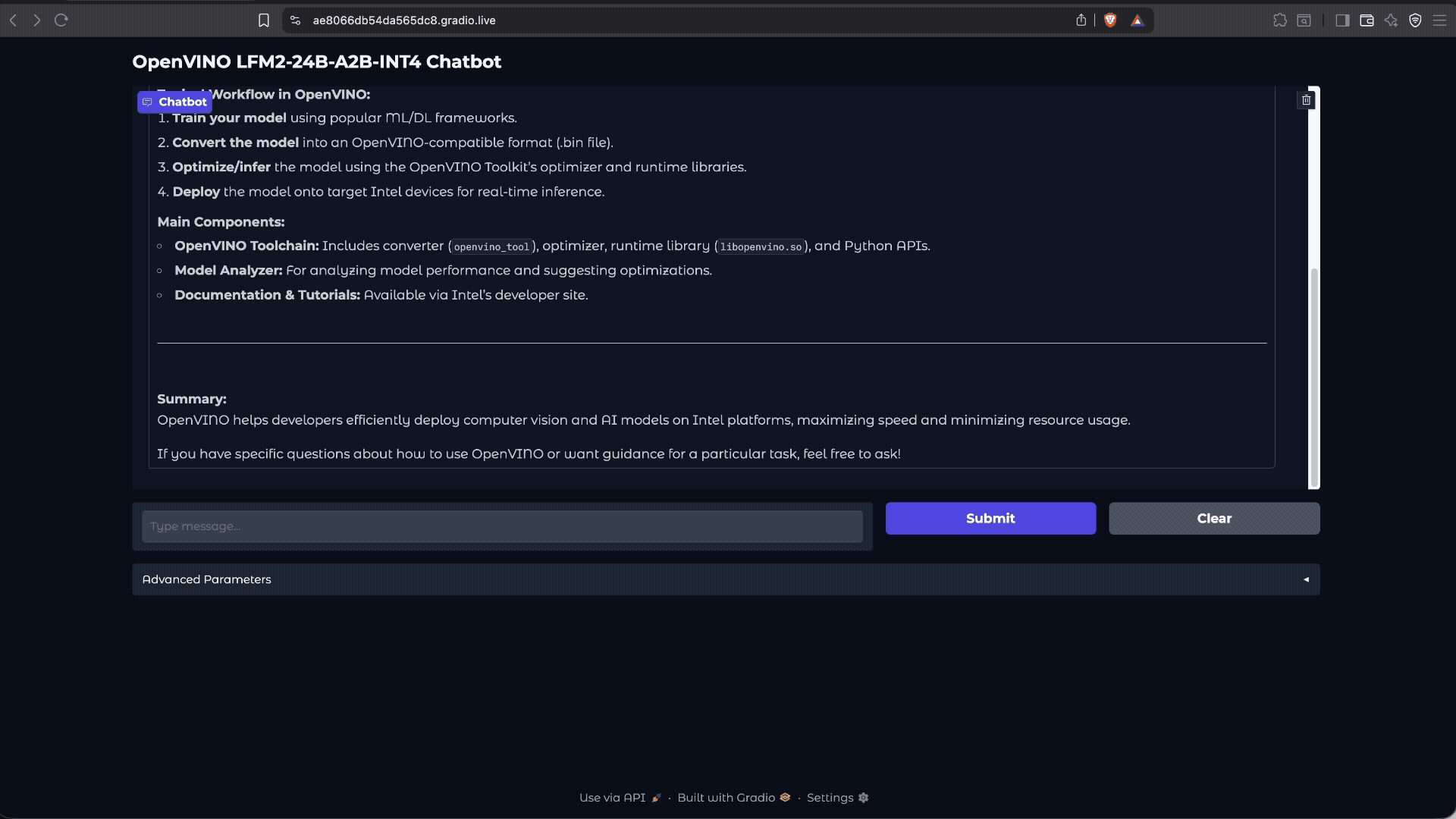
Demo: Simple Local Chatbot
While the LFM2-24B-A2B is designed for high-performance instruction following tasks, this demo shows how it handles a simple question, highlighting the model’s efficiency and responsiveness when running on Intel® Core™ Ultra Series 3 processors with OpenVINO™ optimizations.
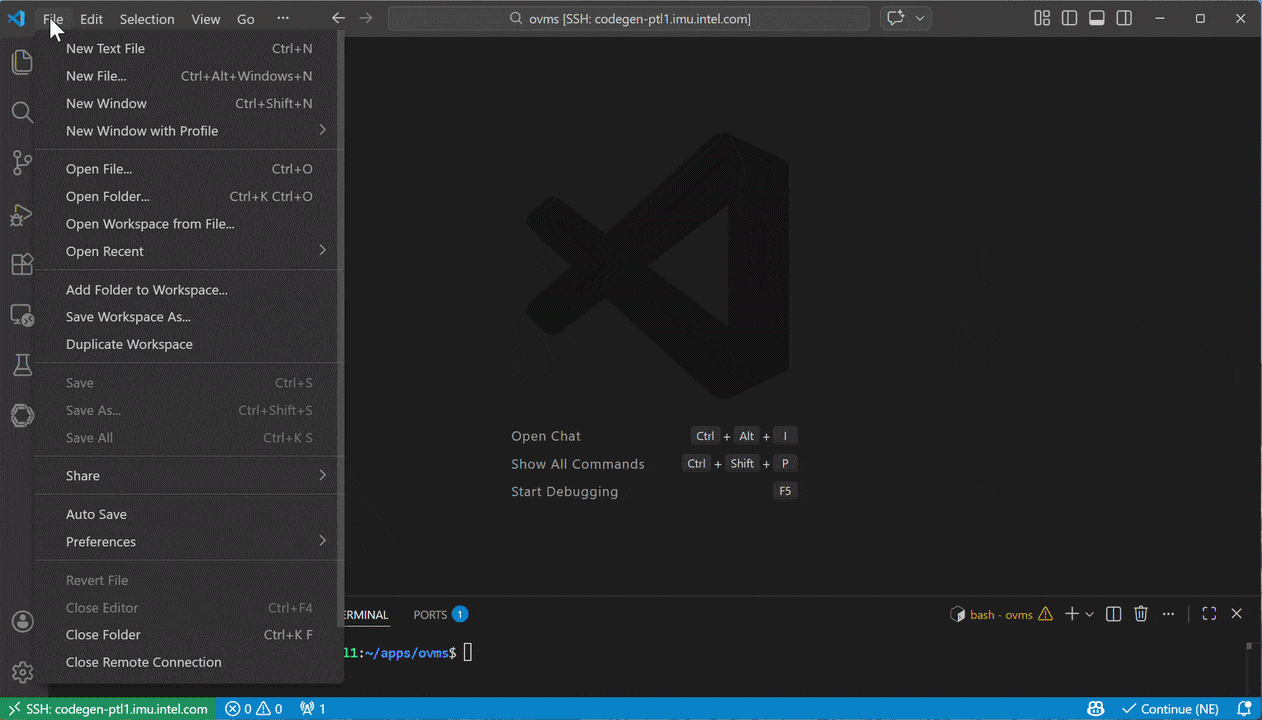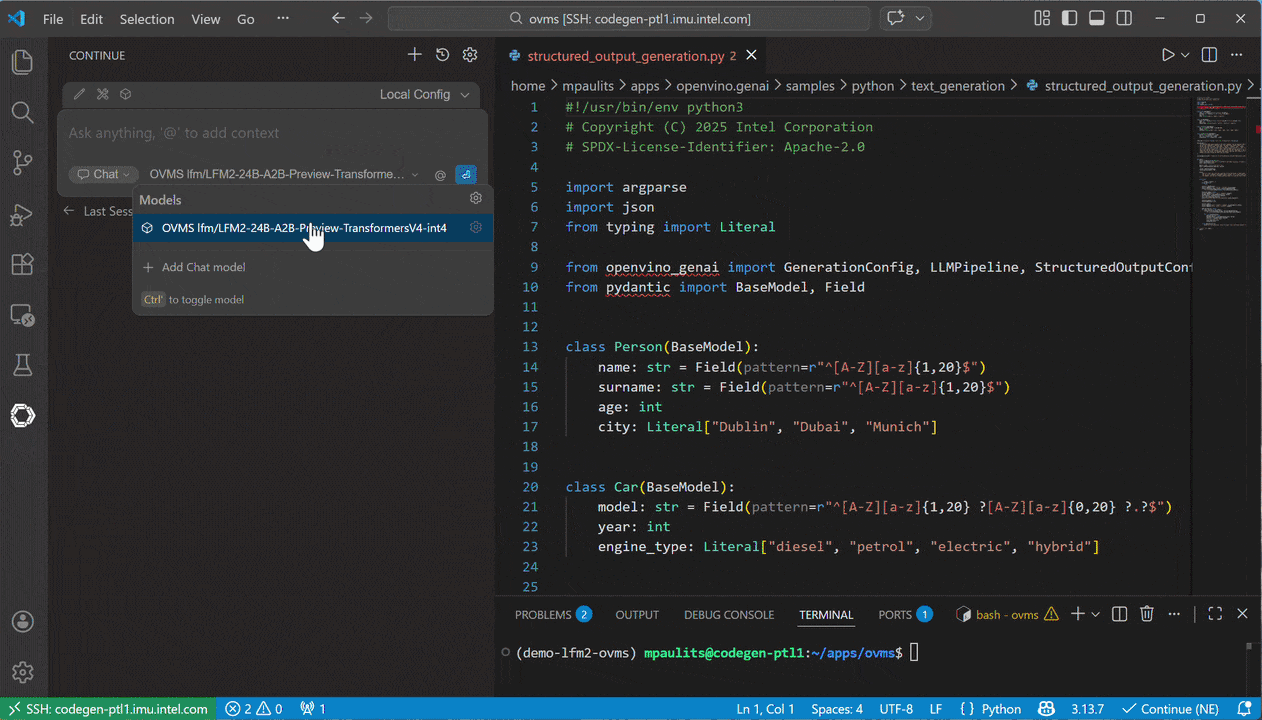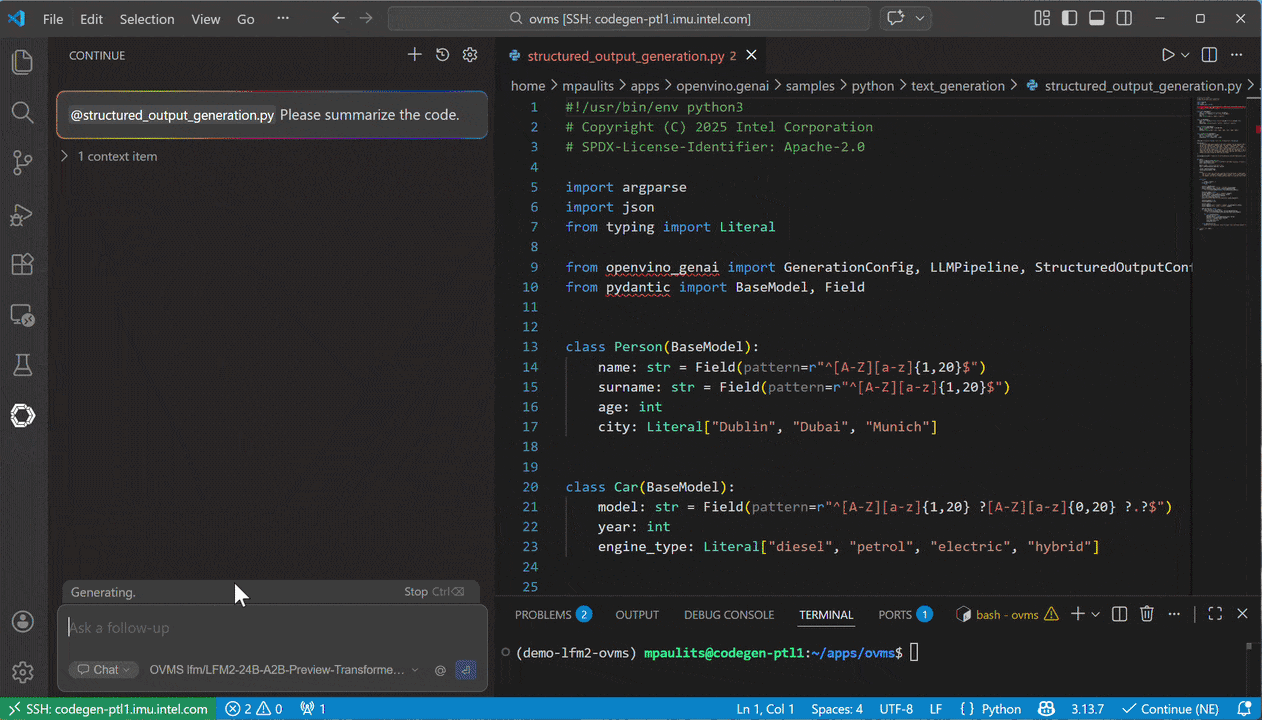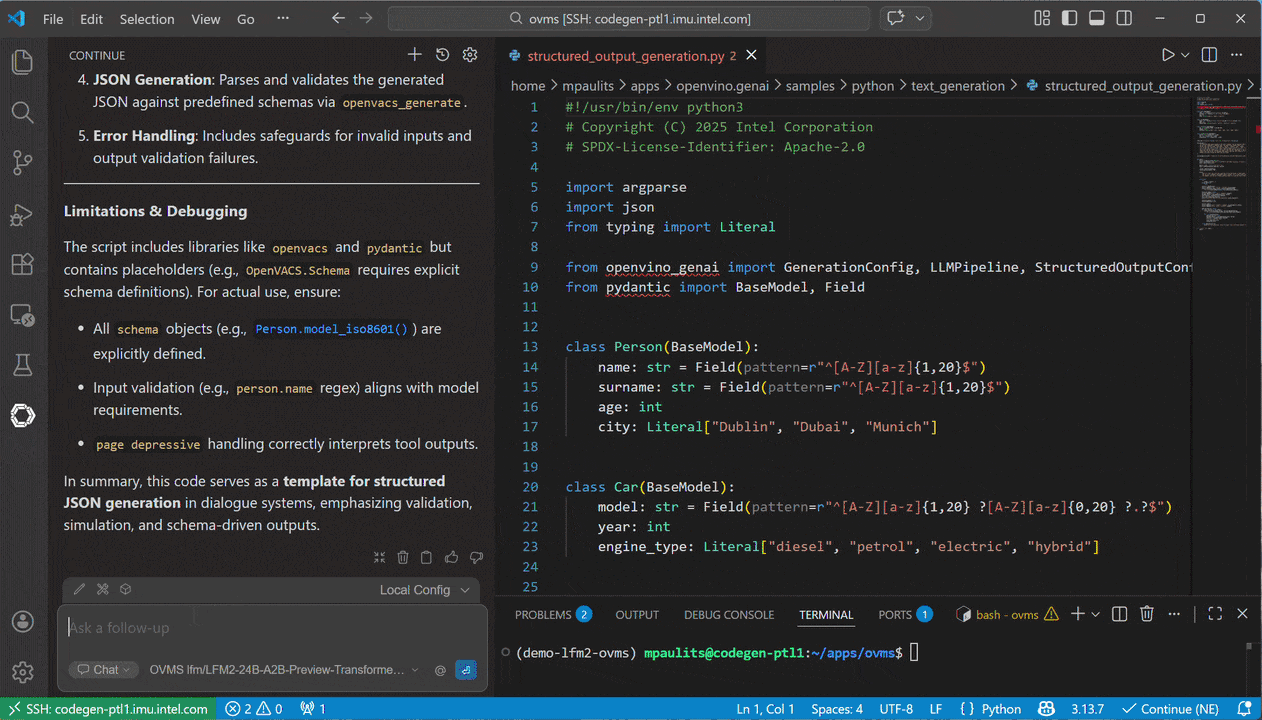
Demo: Efficient Local Coding Support
LFM2-24B-A2B integration into VSCode via Continue extension allows support of efficient local coding tasks. This demo shows a locally generated overview of Python code where a local file is included as context.
Summary
With the optimized LFM2-24B-A2B model for Intel architecture, developers can build powerful on-device AI experiences that are not only fast and responsive but also personalized and private.
To get started with the model, please visit the Hugging Face model card. To learn more about OpenVINO and to download the toolkit, please visit: openvino.ai.
System Configuration Information
Intel® Core™ Ultra X7 Processor 368H Processor Configuration:
- Laptop Model: Intel CSRD (Reference Design)
- CPU: Intel® Core™ Ultra 7 368H processor @ 2 GHz, Memory: 64GB LPDDR5-8535 MT/s, Storage: 1TB
- OS: Ubuntu 25.10, kernel Version: 6.18.1-061801-generic
- Graphics: Intel Arc 140T GPU
- Power Plan: Balanced, Power Mode: Best Performance
- Package Power Limit (W): 65, Short Duration Power Limit (W): 70
- Key Software Version: openvino 2026.1.0 -dev20260224 (lfm2-moe-support), openvino-genai 2026.1.0.0 - dev20260224, openvino-tokenizers 2026.1.0.0 - dev20260224.
Benchmarked on February 24th, 2026.