Intel® XMX Introduction
Intel® Xe Matrix Extensions (Intel® XMX) is a dedicated hardware engine on Intel® Arc™ GPUs for Artificial Intelligence workloads. In comparison to traditional vector units, Intel XMX offers significantly faster AI computation capabilities by accelerating matrix multiplication with specialized Dot Product Accumulate Systolic (DPAS) instructions in 2D systolic arrays. Intel XMX has been widely supported among various Intel products, including Battlemage, the latest discrete GPU, and Lunar Lake, the first laptop SOC that has an integrated GPU using Xe2 architecture.
Running an LLM on ORT-WebGPU
WebGPU is the next generation graphics API on the Web, exposing modern GPU capabilities on top of the native graphics APIs provided by Operating Systems (OS) without any extra software libraries. WebGPU's great performance and portability make it useful not only for the Web but also for native applications. This is why Microsoft* ONNX* (Open Neural Network Exchange) Runtime framework is adopting WebGPU as its Execution Provider (EP) for both Web and native environments.
In WebGPU, a compute shader is executed by a grid of threads. These threads are organized into workgroups, which are collections of threads that run together on a single GPU core. All threads within a workgroup can access the shared workgroup memory.
This memory is allocated and managed by the GPU hardware. It's much faster to access than a global buffer because it's physically closer to the processing cores and has lower latency. However, it's also much smaller, so you have to use it judiciously.
The WebGPU EP of ONNX Runtime is implemented with Dawn – the native WebGPU engine from Chromium* open source project. The diagram below illustrates the architecture of the execution of LLMs on ONNX Runtime with the WebGPU EP on Intel Arc GPUs.

As the diagram shows, Dawn can access the XMX engine either through Direct3D* 12 (D3D12) API or Vulkan* API. As Microsoft has not yet released D3D12 related API specifications, Intel has leveraged the Vulkan API to accelerate LLMs on WebGPU EP of ONNX Runtime with the Intel XMX engine.
MatMulNbits is All You Need
In Transformer architecture, matrix multiplication (MatMul) plays a critical role as the computational backbone. Q/K/V projections, Attention Scores, Weighted Values, Output Projection in the Attention Layer, and two linear transformations in Feed-Forward Network Layer, all hinge on MatMul, making it the foundational engine of Transformer computation. ONNXRuntime introduces the MatMulNBits operator, a high-performance alternative to standard matrix multiplication (MatMul), leveraging N-bit quantization on model weights.
Optimize MatMulNbits with Intel XMX
MatMulNbits kernel computes \(C = A * B\), where:
- A is an M x K row-major matrix in 16-bit floating-point (f16) format.
- B is a K x N quantized matrix stored in 4-bit integers with per-block scaling and zero point for reduced memory bandwidth.
- C is the resulting M x N matrix in f16.
Generally, C = A × B is computed as element-wise dot product. Each element C[m, n] is the sum of pairwise products of rows from A and columns from B:
\(C_{mn} = \displaystyle\sum_{k=0}^{K-1} A_{mk} * B_{kn}\)
The diagram below shows how an element of C is calculated from a row of A and a column of B, where M=4, N=4, K=8, m=1, n=2:
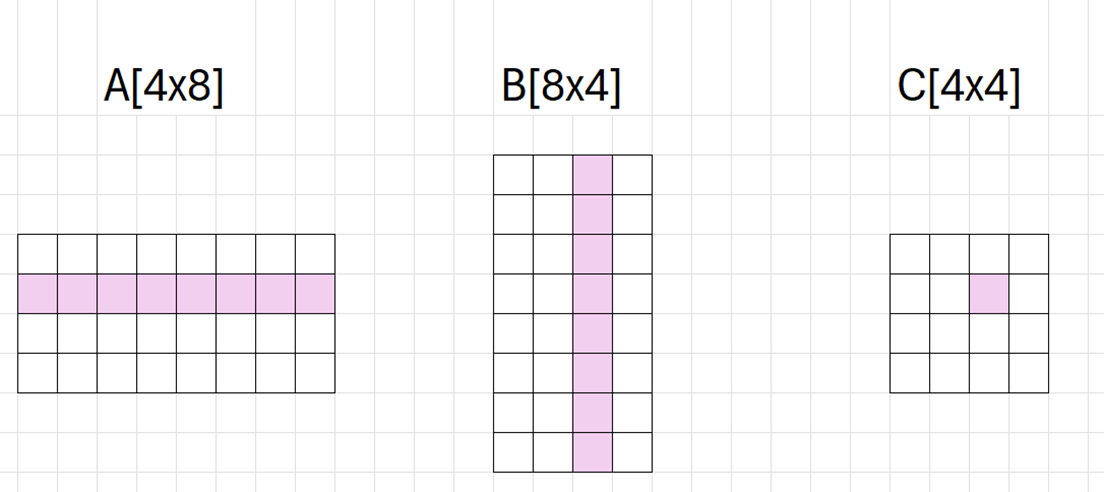
If you turn on the "chromium_experimental_subgroup_matrix" flag in Dawn, such large matrix-multiply-accumulate operations can be decomposed into many smaller, hardware-friendly subgroup matrix operations. The computation is basically the same, except that each element now is a subgroup matrix, and the dimensions of matrices are divided by the dimension of subgroup matrix, as demonstrated by the diagram below, where we assume the subgroup matrix dimension is 2x2:
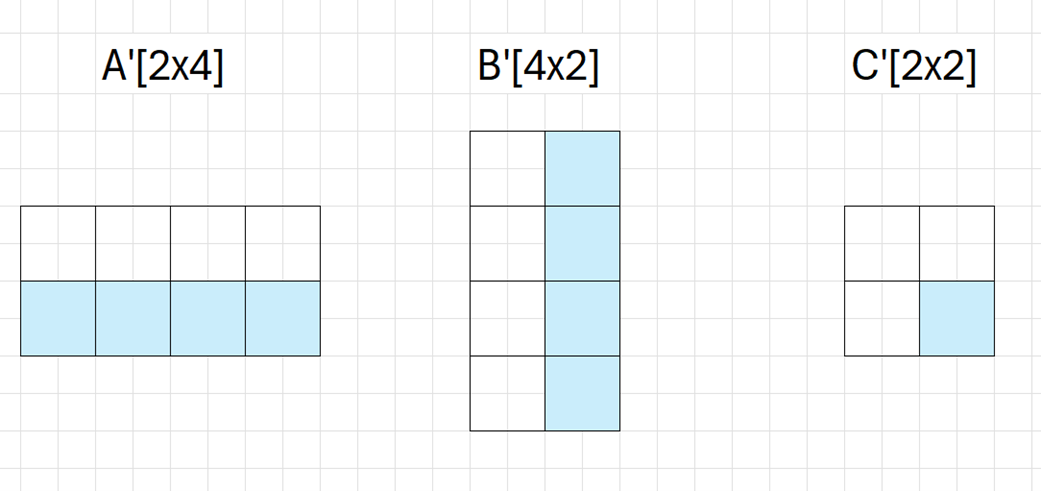
The extension introduces new subgroup_matrix types and built-in functions:
|
Category |
Name |
Description |
|---|---|---|
|
Matrix type |
subgroup_matrix_left<T, K, M> |
M rows x K columns matrix of T type components. |
|
subgroup_matrix_right<T, N, K> |
K rows x N columns matrix of T type components. |
|
|
subgroup_matrix_result<T, N, M> |
M rows x N columns matrix of T type components. |
|
|
I/O function |
subgroupMatrixLoad/Store |
load/store subgroup matrix values from/to global memory or workgroup shared memory. |
|
Arithmetic function |
subgroupMatrixMultiplyAccumulate |
multiply ‘subgroup_matrix_left’ and ‘subgroup_matrix_right’, then accumulate into ‘subgroup_matrix_result’. |
The typical configuration we use on LNL is “T = f16, M = 8, K = 16, N = 16”.
Tile Size Tradeoffs
Matrices A, B, and C are divided into tiles to fit into shared workgroup memory, and then further divided into subgroup matrices for XMX acceleration. This tiling mechanism aims to take advantage of shared workgroup memory, which has much higher bandwidth and much lower latency than global memory. Assume the matrix sizes are M, N, K, and the tile sizes are m, n, k, the total global memory access formula is deduced this way:
- Per \(C\) tile:
- Load \(m * k\) elements of A and \(n * k\) elements of \(B\) in each iteration along with K.
- Total loads per iteration: \(m * k + n * k = (m + n) * k\).
- Number of iterations: \(\frac{K}{k}\).
- Total loads per \(C\) tile: \(\frac{K}{k} * (m+n) * k = K * (m+n)\)
- Total \(C\) tiles: \(\frac{M}{m} * \frac{N}{n}\).
- Final formula: \(\frac{M}{m} * \frac{N}{n} * K * (m+n) = M * N * K * ( \frac{1}{m} + \frac{1}{n} )\).
According to the formula, the larger tile sizes are, the less global memory access there is. However, in the meantime, larger tiles reduce concurrent workgroups due to fixed GPU shared local memory budgets, potentially lowering utilization. We tested different tile sizes (16, 32, 64, 128) and found that m=64 and n=64 worked best.
Direct Global-to-Register Tile Loading
subgroupMatrixLoad can load subgroup matrix values from global memory directly into registers. This bypasses intermediate caching in workgroup shared memory, minimizing consumption of limited shared memory resources, eliminating redundant read/write cycles to shared memory, enhancing workgroup concurrency.
Intel XMX Friendly Matrix Memory Layout
Intel’s compiler optimizes subgroupMatrixLoad for contiguous memory access. To fully take advantage of this, we need to re-arrange the matrix, placing all elements of each subgroup matrix contiguously in global memory. The diagram below shows an example of layout change for a [16x32] matrix consisting of four [8x16] subgroup matrices.
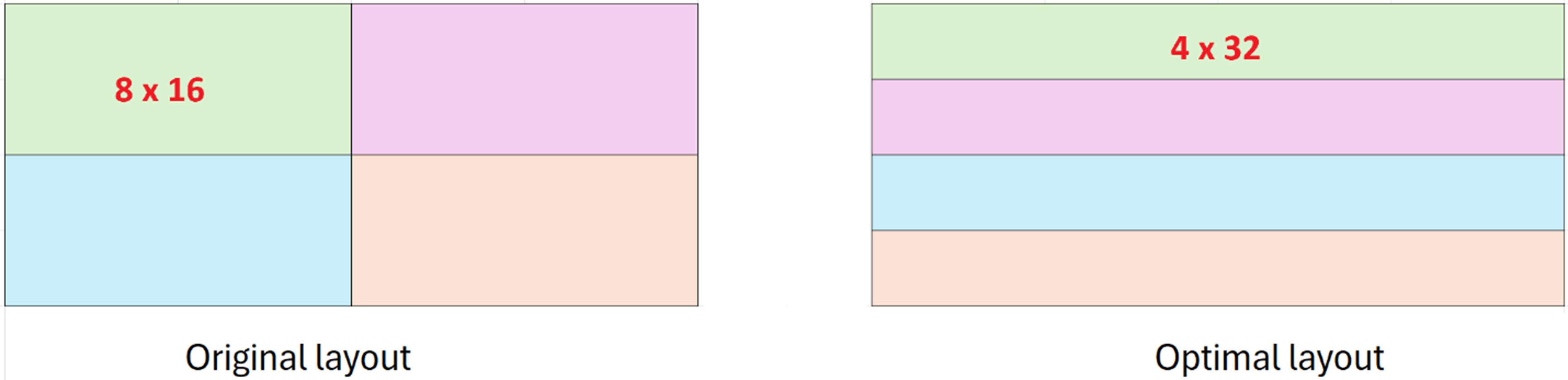
In the original layout, the row stride of subgroup matrix is 32-element instead of 16-element, and rows are not contiguously packed. The optimal layout minimizes scattered memory reads and exploits full cache-line utilization for fewer memory transactions.
Performance Data
We evaluated the performance with the hardware and software configuration below:
- CPU: Intel® Core™ Ultra 7 258V
- GPU: Intel® Arc™ 140V
- Driver Version: 32.0.101.6913
- Model: phi3.5-web-accuracy4-gqa
- ONNX Runtime Version: 440ac68a333de47b6c78afe1e4a4523269c990a0
The performance metrics were:
- Prompt-Length: This refers to the size or complexity of the input data being processed.
- Tokens-Per-Second (TPS): This metric measures the throughput of the system in terms of how many tokens it can process per second.
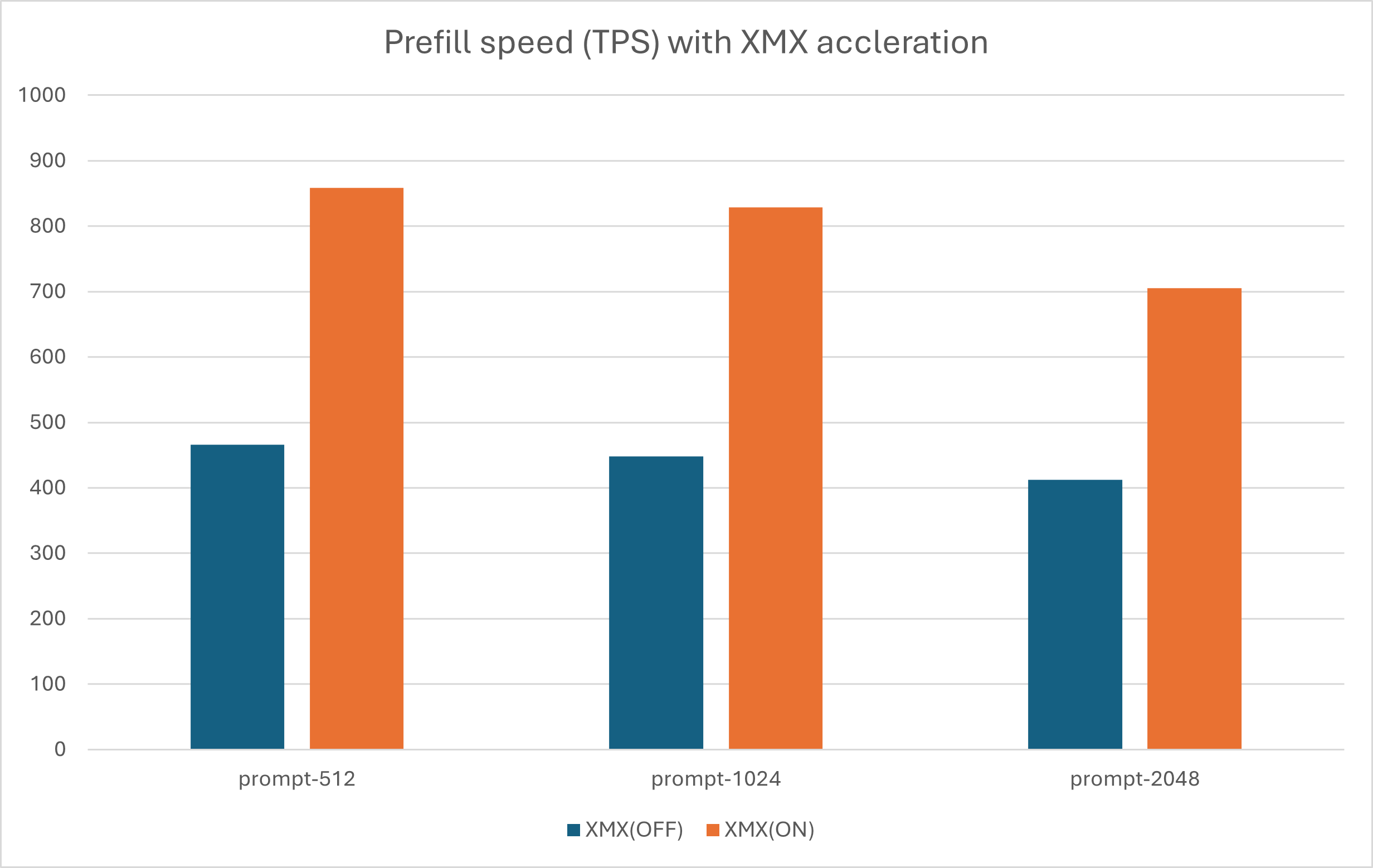
Use Intel XMX Acceleration of ORT-WebGPU on Intel Platforms
There are many popular state-of-the-art ONNX models on Hugging Face* which can benefit from Intel XMX acceleration, such as; Phi-3.5, Qwen3, DeepSeek-R1, and many others.
ORT-WebGPU detects the presence of Dawn ‘chromium_experimental_subgroup_matrix’ extension at runtime and enables Intel XMX acceleration on Intel platforms if available. Applications automatically leverage Intel XMX for faster inference without code changes or reconfiguration. However, the feature currently is only available on Dawn Vulkan backend, so we need to build ORT-WebGPU with 2 extra cmake options:
build.bat --config RelWithDebInfo --parallel --skip_tests --use_webgpu --build_shared_lib
--enable_pybind --build_wheel --cmake_extra_defines onnxruntime_ENABLE_DAWN_BACKEND_VULKAN=ON
--cmake_extra_defines onnxruntime_ENABLE_DAWN_BACKEND_D3D12=OFF
Future Work
- Dawn SubgroupMatrix is not currently available on D3D12. This prevents wide adoption of Intel XMX on Microsoft Windows*. Intel Web Platform team is co-working with the WebGPU community, and stakeholders to enable it as early as possible.
- One promising avenue for further optimization is the switch from fp16 to int8 precision for Intel XMX operations. This transition could reduce memory consumption and potentially boost computational speed, as int8 operations are more memory-efficient compared to fp16, allowing for faster processing and reduced latency.
- Additionally, we plan to optimize the loading of Matrix B with subgroupMatrixLoad as we did for Matrix A. Optimal loading of Matrix B is more complicated, as it requires an extra process to dequantize with block-level scales. With more sophisticated handling, we might deliver more optimization using subgroupMatrixLoad.