
At the Microsoft Build conference in May 2025, we announced our partnership with Microsoft* to enhance the AI experience on Intel powered AI PCs and Copilot+ PCs through the newly launched Windows ML. Our strong collaboration with Microsoft continues as they announce general availability of Windows* ML today. As part of this collaboration, we are introducing the OpenVINO™ Execution Provider for Windows* ML, designed to empower Windows developers to deliver continuous AI innovation with streamlined hardware acceleration across Intel CPUs, GPUs, and NPUs. This integration allows developers to focus on building and deploying AI applications more efficiently, leveraging native Intel optimizations while minimizing integration and deployment overhead.
Seamless AI Deployment: OpenVINO™ Execution Provider for Windows* ML
OpenVINO Execution Provider for Windows ML combines the proven performance and efficiency of OpenVINO AI inferencing software with the ease of development and deployment of Windows ML. This integration enables seamless updates and maintenance of the Execution Provider without requiring application rebuilds or code modifications from developers. The OpenVINO Execution Provider for Windows ML enables developers to maximize performance across Intel's broad x86 ecosystem and multiple generations of Intel platforms, including the latest Intel® Core™ Ultra processors (Series 2), while providing a consistent programming experience across Intel CPUs, GPUs, and NPUs using the same APIs.
ONNX* (Open Neural Network Exchange) model support has been enhanced through deep integration with Intel’s Neural Network Compression Framework (NNCF) and Microsoft’s Olive* toolchain, providing developers with advanced model quantization and optimization capabilities. This collaborative approach meets developers in their existing workflows, providing flexible optimization paths for custom models and wide support for ONNX deployments.
Microsoft’s AI Toolkit for Visual Studio* Code delivers a comprehensive developer ecosystem featuring an extensive model catalog of optimization workflows and examples. The toolkit handles the complex processes of model preparation, including format conversion, quantization, and performance optimization for Intel CPUs, GPUs, and NPUs. Most notably, it also ensures compatibility validation, reducing deployment risks while accelerating time-to-market for AI applications.
Developer Essentials: Code Samples to Get Started
OpenVINO Execution Provider for Windows ML empowers developers to implement AI inference capabilities using their own ONNX models across Intel hardware. A “Bring Your Own Model” sample collection is available that features ResNet-50 and CLIP-ViT for image classification, providing practical implementation blueprints for developers integrating AI into Windows applications. These samples demonstrate the end-to-end workflow from model acquisition through deployment, utilizing the AI Toolkit for Visual Studio code to simplify the model conversion and optimization process, and the OpenVINO Execution Provider for Windows ML to deliver hardware-accelerated inference.
Developers can access these samples and step by step instructions on our GitHub repository.
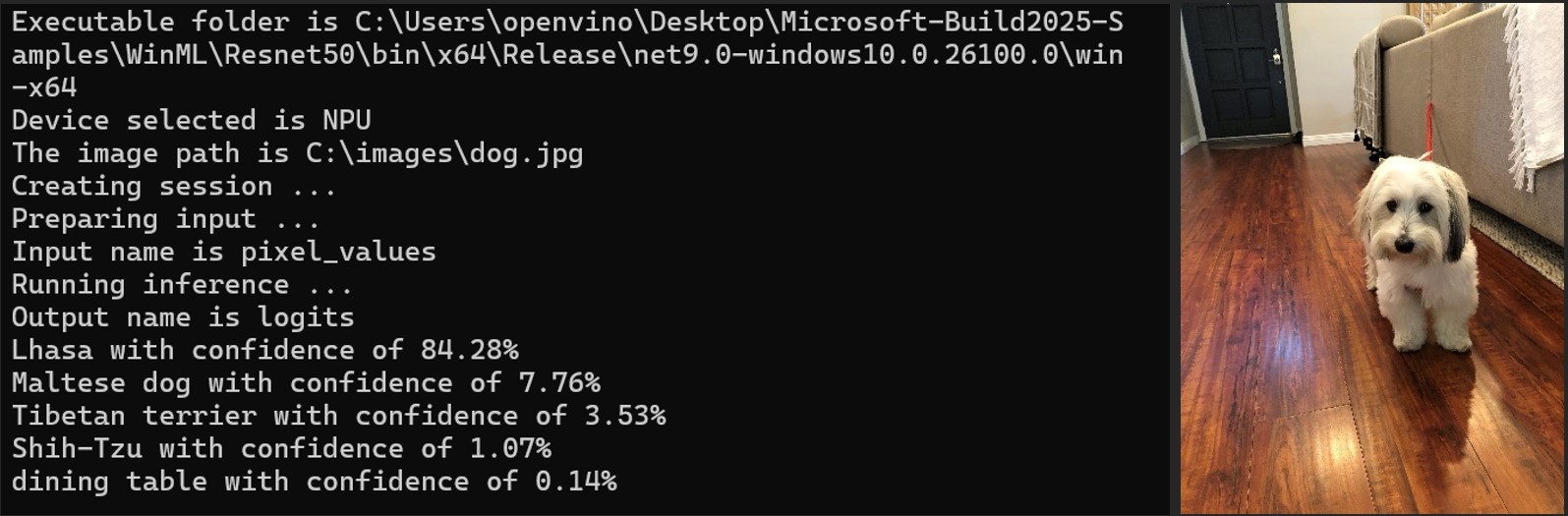
OpenVINO Execution Provider for Windows ML ResNet50 Sample
Building Together: Partnerships & Collaborations
Intel's collaboration with Microsoft on Windows ML accelerates AI development by leveraging OpenVINO integration and enables developers to focus on innovation and deliver faster, smarter AI applications for Windows users on Intel powered AI PCs and Copilot+ PC.
“Windows ML is optimized for Intel CPUs, GPUs, and NPUs, enabling powerful client AI experiences through Intel’s OpenVINO Execution Provider. Our partnership is critical to scaling our collective AI ambitions, and we are excited Windows ML is generally available today with seamless support for Intel’s capable silicon.”
— Logan Iyer, VP, Distinguished Engineer, Windows Platform & Developer
Since the launch of Windows ML, Intel has continued collaborating with BUFFERZONE® Safe Workspace®, an endpoint security solution that prevents external attacks through application isolation and NoCloud® AI technology. BUFFERZONE® has partnered with Intel to enable AI inference acceleration on Intel hardware, leveraging ONNX and OpenVINO™ GenAI to accelerate development cycles and reduce time-to-market.
“AI-powered PCs are redefining the future of endpoints, and at BUFFERZONE®, we are leading this shift for endpoint security. With our NoCloud® AI technology built on Windows ML, AI workloads can efficiently run on both the AI PC NPU and GPU. Windows ML streamlines development and accelerates adoption, helping new AI-driven use cases reach the market sooner. For customers, this means extracting even more value from Copilot+ PCs and AI PCs powered by Intel Core Ultra processors.”
— Dr. Ran Dubin, CTO, BUFFERZONE®
Intel and Wondershare* have a close engineering collaboration to enable innovative user experiences for AI PCs powered by Intel Core Ultra processors. From Automatic Portrait Cutout to Special Effects, the next wave of AI features from Wondershare leverage Windows ML to further enhance the creator experience.
"Wondershare Filmora* reaches millions of users worldwide with our initiative of providing AI experiences for all video creators. We collaborate with Intel to harness the AI capabilities of Intel AI PCs by leveraging integrated Intel AI accelerators (CPUs, GPUs, and NPUs) through the use of Windows ML together with the OpenVINO Execution Provider for Windows ML.”
— Rocky Tang, Head of Business, Wondershare*