| File(s): | GitHub |
| License: | MIT |
| Optimized for... | |
|---|---|
| Software: (Programming Language, Tool, IDE, Framework) |
Intel® oneAPI DPC++/C++ Compiler |
| Prerequisites: | Familiarity with C++ and an interest in SYCL* |
This tutorial describes parallel implementations for adding two vectors using SYCL*. The two code samples, showing two different memory management techniques (vector-add-buffers.cpp and vector-add-usm.cpp), are available on GitHub. You can use these samples as a starting point for developing more complex applications.
This tutorial and its code examples use the Intel® oneAPI DPC++/C++ Compiler and assume that the compiler and its environment have been set up and configured correctly. Building and running these samples will verify that your development environment is ready to use the core features of SYCL.
Introduction
Some basic attributes of writing SYCL applications include specifying the device for offload, where kernels execute, and managing the interaction and data propagation between the device and the host. In these samples, you will learn how to write the kernel and use two memory management techniques: Buffers and Unified Shared Memory (USM).
The samples use two .cpp files to demonstrate the options independently:
- vector-add-buffers.cpp uses buffers and accessors to perform memory copy to and from the device. Buffers provide data mapping between the host and the accelerator. 1-, 2-, or 3-dimensional arrays are placed into buffers while submitting work to a queue. The queue provides work scheduling, orchestration, and high-level parallel operations. Work is submitted to the queue using a lambda that encapsulates the work kernel and the data needed for its execution. Buffers are initialized on the host and accessed by the lambda. The lambda requests read access for the input vectors and write access for the output vector.
- vector-add-usm.cpp uses USM as a SYCL tool for data management. It uses a pointer-based approach like malloc or new to allocate memory. USM requires hardware support for unified virtual address space (this allows for consistent pointer values between the host and device). The host allocates all memory. It offers three distinct allocation types:
- Shared: Located on the host or device (managed by the compiler), accessible by the host or device.
- Device: Located on the device, accessible only by the device.
- Host: Located on the host, accessible by the host or device.
The following diagram illustrates the difference between the two:
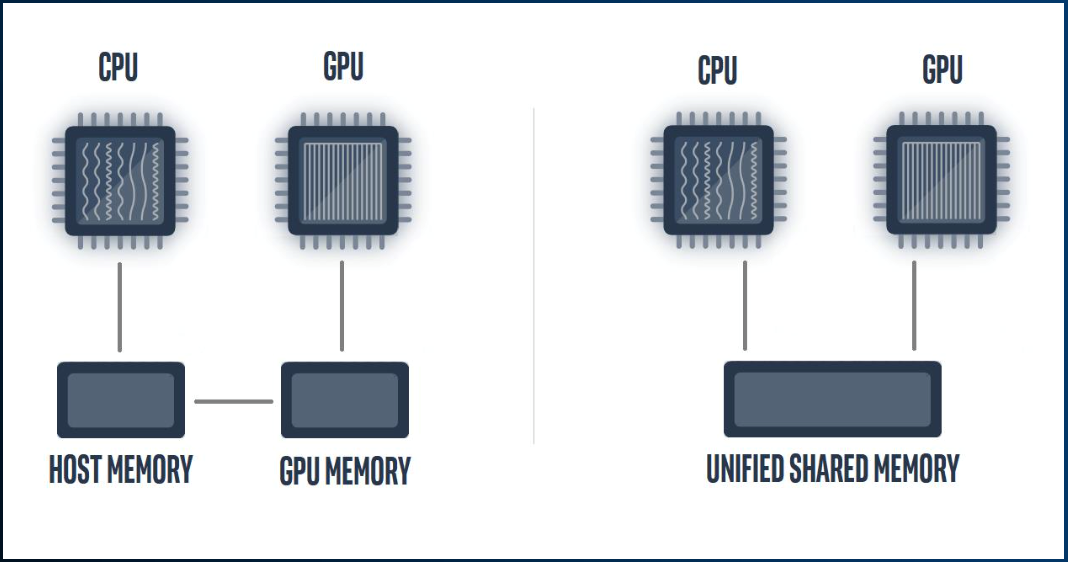
Left: both the host and the device (for example, discrete GPU) may have their physical memories. Right: the logical view of USM. It provides a unified address space across the host and the device, even when their memories are physically separate.
Problem Statement
You can compute a vector from two vectors by adding the corresponding elements. This simple but fundamental computation is used in many linear algebra algorithms and in applications in a wide range of areas. Using this problem, this tutorial demonstrates two parallel implementations using SYCL buffers and USM. It also provides a sequential implementation to verify that the result of the offloaded computation is correct.
Parallel Implementation and Sample Code Walkthrough
Sample 1: Buffers
This code sample explains the basic SYCL implementation, which includes a device selector, queue, buffer, accessor, kernel, and command group.
Create Device Selector
Using SYCL, you can offload computation from the CPU to a device. The first step is to select a device (the sample uses FPGA). Based on the availability of devices and their intended use cases, create a device selector object:
- Default selector: default_selector_v
- For FPGA: INTEL::fpga_selector_v
- For an FPGA emulator: INTEL::fpga_emulator_selector_v
This sample uses definitions to choose between device selectors; you can pick between FPGA, FPGA emulator, or the default device. The appropriate definition can be provided when compiling the sample to create the intended device selector object. The makefile illustrates how to specify such a definition. The default device selector object is created if no device selector definition is explicitly specified during compile time. This has the advantage of selecting the most performant device among the available devices during runtime. If you do not intend to use either an FPGA or an FPGA emulator, then you can omit to specify a definition, and the default device selector object is created.
int main(int argc, char* argv[]) {
// Change num_repetitions if it was passed as argument
if (argc > 2) num_repetitions = std::stoi(argv[2]);
// Change vector_size if it was passed as argument
if (argc > 1) vector_size = std::stoi(argv[1]);
// Create device selector for the device of your interest.
#if FPGA_EMULATOR
// Intel extension: FPGA emulator selector on systems without FPGA card.
auto selector = sycl::ext::intel::fpga_emulator_selector_v;
#elif FPGA_SIMULATOR
// Intel extension: FPGA simulator selector on systems without FPGA card.
auto selector = sycl::ext::intel::fpga_simulator_selector_v;
#elif FPGA_HARDWARE
// Intel extension: FPGA selector on systems with FPGA card.
auto selector = sycl::ext::intel::fpga_selector_v;
#else
// The default device selector will select the most performant device.
auto selector = default_selector_v;
#endif
Create a Command Queue
The next step is to create a command queue. Any computation you want to offload to a device is queued/submitted to the command queue. This sample instantiates a command queue by passing the following arguments to its constructor:
- A device selector.
- An exception handler.
The first argument, the device selector, is what you created in the Create Device Selector section above. The second argument, the exception handler, is needed to handle any asynchronous exception that the offloaded computation may encounter at the time of execution. An exception_handler has been implemented to handle async exceptions:
queue q(selector, exception_handler);
The exception_handler handles exceptions by invoking std::terminate()to terminate the process. The handler prints Failure as a message on debug builds and then terminates the process.
You can provide your own exception handler if you want to handle exceptions differently without terminating the process.
Create and Initialize Vectors
For a VectorAdd operation, you need two vectors as inputs and a third vector to store the result. This sample creates two vectors for a result. One is the output vector for sequential computation performed on the host, and the other result vector is used to retain the output from the parallel computation performed on the device.
Two input vectors are initialized with values: 0, 1, 2, …
Allocate Device Visible Memory
To compute on the device, you need to make the input vectors visible to it and copy back the computed result to the host.
Along with offloading the compute on the device, this sample demonstrates how to make input visible to the device and copy back the computed result from the device. There are two major options to achieve this goal:
- Buffers and accessors
- USM
Buffers and Accessors
This code sample uses buffers and accessors. Below is a high-level summary of this technique and the relevant code snippets.
Create Buffers
This implementation demonstrates two ways to create buffers. Either pass a reference to a C++ container to the buffer constructor or pass a pointer and a size as arguments to the buffer constructor. The first option is useful when your data is in C++/STL containers. The second option is useful when the data is in regular C/C++ arrays and vectors, for example:
// Create buffers that hold the data shared between the host and the devices.
// The buffer destructor is responsible to copy the data back to host when it
// goes out of scope.
buffer a_buf(a_vector);
buffer b_buf(b_vector);
buffer sum_buf(sum_parallel.data(), num_items);
Create Accessors
You can create accessors from respective buffer objects by specifying the data access mode. With VectorAdd, the device accesses the first two vectors to read inputs and the third vector to write output. The input vector/buffer, a_buf, specifies read_only as an access mode to obtain the appropriate accessor. The output vector/buffer, sum_buf, specifies write_only as an access mode.
Specifying the appropriate access mode is required for correctness and performance. Write access for the output vector tells the Intel® oneAPI DPC++/C++ Compiler that the result computed on the device must be copied back to the host at the end of the computation. This is required for correctness. At the same time, the compiler avoids copying the content of the result vector from the host to the device before performing computation on the device. This step improves performance by avoiding an extra copy from the host to the device. This is correct because the computation writes/overwrites sum_buf.
// Create an accessor for each buffer with access permission: read, write or
// read/write. The accessor is a mean to access the memory in the buffer.
accessor a(a_buf, h, read_only);
accessor b(b_buf, h, read_only);
// The sum_accessor is used to store (with write permission) the sum data.
accessor sum(sum_buf, h, write_only, no_init);
Command Group Handler
The SYCL runtime constructs the command group handler object. All accessors, defined in a command group, take the command group handler as an argument. That way, the runtime keeps track of the data dependencies. The kernel invocation functions are member functions of the command group handler class. A command group handler object cannot be copied or moved.
parallel_for
parallel_for is a commonly used SYCL programming construct. While iterations of C++ for a loop run sequentially, multiple logical iterations of parallel_for can run simultaneously by multiple execution/compute units of the device. As a result, the overall compute runs fast when parallel_for is used. It is suitable for data parallel compute where each logical iteration executes the same code. Still, it operates on different pieces of data (also known as single instruction multiple data (SIMD)). parallel_for is optimal when there is no data dependency between logical iterations.
In this sample, you can use parallel_for because the corresponding elements from two input vectors can be independently and parallelly added to compute individual elements of the resultant vector, with no dependency on other elements of the input or output vectors. parallel_for is used to offload the compute onto the device. The first argument is the number of work items. For VectorAdd, the number of work items is simply the number of vector elements. The second argument is the kernel encapsulating the compute for each work item. Each work item is responsible for computing the sum of two elements from two input vectors and writing the sum operation's result to the output vector's corresponding element.

The offloaded work (parallel_for) continues asynchronously on the device. The last statement of the following code snippet waits for this asynchronous operation to complete.
// Use parallel_for to run vector addition in parallel on device. This
// executes the kernel.
// 1st parameter is the number of work items.
// 2nd parameter is the kernel, a lambda that specifies what to do per
// work item. The parameter of the lambda is the work item id.
// SYCL supports unnamed lambda kernel by default.
h.parallel_for(num_items, [=](auto i) { sum[i] = a[i] + b[i]; });
});
};
Kernel for Vector Add (Parallel Compute on the Device)
The compute is offloaded to the device by submitting a lambda function to the command queue. The device accesses two input vectors and the output vector through the accessors. The previous sections covered how buffers and accessors are set up and how parallel_for computes the result vector.
Before the result buffer (sum_buf) goes out of scope, the SYCL runtime copies the computed result from the device memory to the host memory.
// Submit a command group to the queue by a lambda function that contains the
// data access permission and device computation (kernel).
q.submit([&](handler &h) {
// Create an accessor for each buffer with access permission: read, write or
// read/write. The accessor is a mean to access the memory in the buffer.
accessor a(a_buf, h, read_only);
accessor b(b_buf, h, read_only);
// The sum_accessor is used to store (with write permission) the sum data.
accessor sum(sum_buf, h, write_only, no_init);
// Use parallel_for to run vector addition in parallel on device. This
// executes the kernel.
// 1st parameter is the number of work items.
// 2nd parameter is the kernel, a lambda that specifies what to do per
// work item. The parameter of the lambda is the work item id.
// SYCL supports unnamed lambda kernel by default.
h.parallel_for(num_items, [=](auto i) { sum[i] = a[i] + b[i]; });
});
};
Sample 2: USM
USM offers three types of allocations: device, host, and shared. This sample uses shared allocations.
Shared allocations are accessible on the host and the device. They are like host allocations, but they differ in that data can now migrate between host memory and device-local memory. This means that access on a device, after the migration from the host memory to the device local memory has completed, comes from the device local memory instead of remotely accessing the host memory. The SYCL runtime and lower-level drivers accomplish this. Shared allocations use implicit data movement. With this type of allocation, you do not need to explicitly insert copy operations to move data between the host and device. Instead, you access data using the pointers inside a kernel, and any required data movement is performed automatically. This simplifies moving your existing code to SYCL by replacing any malloc or new with the appropriate SYCL USM allocation functions. Shared allocation is supported via software abstraction, like SYCL buffer or device allocation. The only advantage is that the data is implicitly migrated rather than explicitly. With the necessary hardware support, the page migration starts (the data will migrate page-by-page between the host and the device). With page migration, computation overlaps with incremental data movement without waiting for the data transfer to complete. This implicit overlap potentially increases the throughput of the computation. This is an advantage of using shared allocation. On the other hand, with device allocation and SYCL buffers, the computation does not start until the data transfer is complete.
Memory Allocation and Memory Free
Use malloc_shared() to allocate shared memory accessible to both the host and the device. The two arguments are:
- The number of elements in a vector.
- The queue (associated with a device to offload the compute).
Use free() to release memory. Using free() in SYCL is similar to how you would use it with C++, but SYCL uses an extra argument with the queue:
// Create arrays with "array_size" to store input and output data. Allocate
// unified shared memory so that both CPU and device can access them.
int *a = malloc_shared<int>(array_size, q);
int *b = malloc_shared<int>(array_size, q);
int *sum_sequential = malloc_shared<int>(array_size, q);
int *sum_parallel = malloc_shared<int>(array_size, q);
if ((a == nullptr) || (b == nullptr) || (sum_sequential == nullptr) ||
(sum_parallel == nullptr)) {
if (a != nullptr) free(a, q);
if (b != nullptr) free(b, q);
if (sum_sequential != nullptr) free(sum_sequential, q);
if (sum_parallel != nullptr) free(sum_parallel, q);
std::cout << "Shared memory allocation failure.\n";
return -1;
}
Use USM
Like Sample 1, this sample uses parallel_for to add two vectors. e.wait() waits for everything submitted to the queue before it completes. For example, a copy back computed result from the device local memory to the host memory:
// Create the range object for the arrays.
range<1> num_items{size};
// Use parallel_for to run vector addition in parallel on device. This
// executes the kernel.
// 1st parameter is the number of work items.
// 2nd parameter is the kernel, a lambda that specifies what to do per
// work item. The parameter of the lambda is the work item id.
// SYCL supports unnamed lambda kernel by default.
auto e = q.parallel_for(num_items, [=](auto i) { sum[i] = a[i] + b[i]; });
// q.parallel_for() is an asynchronous call. SYCL runtime enqueues and runs
// the kernel asynchronously. Wait for the asynchronous call to complete.
e.wait();
}
Verification of Results
Once the computation is complete, you can compare the outputs from sequential and parallel computations to verify that the execution on the device computed the same result as on the host:
// Compute the sum of two arrays in sequential for validation.
for (size_t i = 0; i < array_size; i++) sum_sequential[i] = a[i] + b[i];
If the verification is successful, a few elements from input vectors and the result vector are printed to show the output of the computation:
// Print out the result of vector add.
for (int i = 0; i < indices_size; i++) {
int j = indices[i];
if (i == indices_size - 1) std::cout << "...\n";
std::cout << "[" << j << "]: " << j << " + " << j << " = "
<< sum_sequential[j] << "\n";
}
free(a, q);
free(b, q);
free(sum_sequential, q);
free(sum_parallel, q);
} catch (exception const &e) {
std::cout << "An exception is caught while adding two vectors.\n";
std::terminate();
}
std::cout << "Vector add successfully completed on device.\n";
return 0;
}
Summary
This tutorial demonstrates the basic features commonly used in a SYCL program, including creating a queue, basic memory management (using buffers and accessors or USM), writing a kernel to offload compute to the device, and more. You can use this tutorial as a starting point for developing more complex applications.
Resources
- The Intel® oneAPI Toolkits site has detailed descriptions of SYCL and oneAPI toolkits.
- For more documentation and code samples, see the Featured Documentation on the Intel® oneAPI Toolkits site.