| File(s): |
Download |
| License: | 3-Clause BSD License |
| Optimized for... | |
|---|---|
| OS: | Linux* kernel version 4.3 or higher |
| Hardware: | Emulated: See How to Emulate Persistent Memory Using Dynamic Random-access Memory (DRAM) |
| Software: (Programming Language, tool, IDE, Framework) |
C++ Compiler, JDK, Persistent Memory Developers Kit (PMDK) libraries and Persistent Collections for Java* (PCJ) |
| Prerequisites: | Familiarity with C++ and Java |
Introduction
In this article, I present an introduction to the Persistent Collections for Java* (PCJ) API for persistent memory programming. This API emphasizes persistent collections, since collection classes map well to the use cases observed for many persistent memory applications. I show how it is possible to instantiate and store a persistent collection (without serialization), as well as fetch it later after a power cycle. A full example, comprised of a persistent array of employees (being an Employee a custom persistent class implemented from scratch) is described in detail (including source code). I finalize the article by showing how Java programs using PCJ can be compiled and run.
Why Do We Need APIs?
At the core of the NVM Programming Model (NPM) standard, developed by key players in the industry through the Storage and Networking Industry Association (SNIA), we have memory-mapped files. This model was chosen primarily to avoid reinventing the wheel, given that the majority of problems they were trying to solve (such as how to collect, name, and find memory regions, or how to provide access control, permissions, and so on) were already solved by file systems (FS). In addition, memory-mapped files have been around for decades. Thus, they are stable, well understood, and widely supported. Using a special FS, processes running in user space can (after opening and mapping a file) access this mapped memory directly without involving the FS itself, in turn avoiding expensive block caching/flushing and context switching to/from the operating system (OS).
Programming directly against memory-mapped files, however, is not trivial. Even if we avoid block caching on dynamic random-access memory (DRAM), some of the most recent data writes may still reside—unflushed—in the CPU caches. Unfortunately, these caches are not protected against a sudden loss of power. If that were to happen while part of our writes are still sitting unflushed in the caches, we may end up with corrupted data structures. To avoid that, programmers need to design their data structures in such a way that temporary torn-writes are allowed, and make sure that the proper flushing instructions are issued at exactly the right time (too much flushing is not good either because it impacts performance).
Fortunately, Intel has developed the Persistent Memory Developer Kit (PMDK), an open source collection of libraries and tools that provide low-level primitives as well as useful high-level abstractions to help persistent memory programmers overcome these obstacles. Although these libraries are implemented in C, there has been a significant effort to provide APIs for other popular languages, including C++, Java* (which is the topic of this article) and Python*. Although the APIs for Java and Python are still early (experimental) solutions, work is in progress and evolving quickly.
Persistent Collections for Java* (PCJ)
The API provided for persistent memory programming in Java emphasizes persistent collections. The reason is that collection classes map well to the use cases observed for many persistent memory applications. Instances of these classes persist (that is, remain reachable) beyond the life of the Java virtual machine (JVM) instance. In addition to built-in classes, programmers can define their own persistent classes (as we will see next). There is even the possibility to create our own abstractions through a low-level accessor API (in the form of a MemoryRegion interface), but that is out of the scope of this article.
The following are the persistent collections supported in the API:
- Persistent primitive arrays:
PersistentBooleanArray, PersistentByteArray, PersistentCharArray, PersistentDoubleArray, PersistentFloatArray, PersistentIntArray, PersistentLongArray, PersistentShortArray - Persistent array:
PersistentArray<AnyPersistent> - Persistent tuple:
PersistentTuple<AnyPersistent, …> - Persistent array list:
PersistentArrayList<AnyPersistent> - Persistent hash map:
PersistentHashMap<AnyPersistent, AnyPersistent> - Persistent linked list:
PersistentLinkedList<AnyPersistent> - Persistent linked queue:
PersistentLinkedQueue<AnyPersistent> - Persistent skip list map:
PersistentSkipListMap<AnyPersistent, AnyPersistent> - Persistent FP tree map:
PersistentFPTreeMap<AnyPersistent, AnyPersistent> - Persistent SI hash map:
PersistentSIHashMap<AnyPersistent, AnyPersistent>
Similar to the C/C++ libpmemobj library in PMDK, we need a common root object to anchor all the other objects created in the persistent memory pool. In the case of PCJ, this is accomplished through a singleton class called ObjectDirectory. Internally, this class is implemented using a hash map object of type PersistentHashMap<PersistentString, AnyPersistent>, which means that we can use human-readable names to store and fetch our objects, as shown in the following code snippet:
...
PersistentIntArray data = new PersistentIntArray(1024);
ObjectDirectory.put("My_fancy_persistent_array", data); // no serialization
data.set(0, 123);
...
This code first allocates a persistent array of integers of size 1024. After that, it inserts a reference to it into ObjectDirectory named "My_fancy_persistent_array". Finally, the code writes an integer to the first position of the array. Realize that, in this case, if we were to not insert a reference into the object directory and then lose the last reference to the object (for example, by doing data = null), the Java garbage collector (GC) would collect the object and free its memory region from the persistent pool (that is, the object would be lost forever). This does not happen in the C/C++ libpmemobj library; in a similar situation, a persistent memory leak would occur (although leaked objects can be recovered).
The following code snippet shows how we can fetch our object after a power cycle:
...
PersistentIntArray old_data = ObjectDirectory.get("My_fancy_persistent_array",
PersistentIntArray.class);
assert(old_data.get(0) == 123);
...
As you can see, there is no need to instantiate a new array. The variable old_data is directly assigned to the object named "My_fancy_persistent_array" stored in persistent memory. An assert() is used here to make sure that this is, in fact, the same array.
A Full Example
Let's take a look now at a full example to see how all the pieces fall into place (you can download the source from GitHub*).
import lib.util.persistent.*;
@SuppressWarnings("unchecked")
public class EmployeeList {
static PersistentArray<Employee> employees;
public static void main(String[] args) {
// fetching back main employee list (or creating it if it is not there)
if ((employees = ObjectDirectory.get("employees", PersistentArray.class)) == null) {
employees = new PersistentArray<Employee>(64);
ObjectDirectory.put("employees", employees);
System.out.println("Storing objects");
// creating objects
for (int i = 0; i < 64; i++) {
Employee employee = new Employee(i,
new PersistentString("Fake Name"),
new PersistentString("Fake Department"));
employees.set(i, employee);
}
} else {
// reading objects
for (int i = 0; i < 64; i++)
if ((employees.get(i).getId() == i) == true)
System.out.print("OK ");
else {
System.out.print("FAIL ");
break;
}
System.out.print("\n");
}
}
}
The above code listing corresponds to the class EmployeeList (defined in the EmployeeList.java file), which contains the main() method for the program. This method tries to get a reference for the persistent array "employees". If the reference does not exist (that is, return value is null), then a new PersistentArray object of size 64 is created and a reference stored in the ObjectDirectory. Once that is done, the array is filled with 64 employee objects. If the array exists, we iterate it making sure the values of the employee IDs are the ones we inserted before.
Some details regarding this code are worth mentioning here. First, there is the need to import the needed classes contained in the package under lib.util.persistent.*. Included in those are not only the persistent collections themselves, but also basic classes for persistent memory such as PersistentString. If you have some experience with the C/C++ interface, you may be wondering where we are passing to the library the location of the pool file and its size. In the case of PCJ, this is done with a configuration file called config.properties (which needs to reside on the current working directory). The following example sets the pool's path to /mnt/mem/persistent_heap and its size to 2GB (this assumes that a persistent memory device—real or emulated using RAM—is mounted at /mnt/mem):
$ cat config.properties
path=/mnt/mem/persistent_heap
size=2147483648
$
As I mentioned above, we can define our own persistent classes for the cases where simple types (such as integers, strings, and so on), are not enough and more complex types are needed. This is exactly what we have done with the class Employee in this example. The class is shown in the following listing (you can find it in the file Employee.java):
import lib.util.persistent.*;
import lib.util.persistent.types.*;
public final class Employee extends PersistentObject {
private static final LongField ID = new LongField();
private static final StringField NAME = new StringField();
private static final StringField DEPARTMENT = new StringField();
private static final ObjectType<Employee> TYPE =
ObjectType.withFields(Employee.class, ID, NAME, DEPARTMENT);
public Employee (long id, PersistentString name, PersistentString department) {
super(TYPE);
setLongField(ID, id);
setName(name);
setDepartment(department);
}
private Employee (ObjectPointer<Employee> p) {
super(p);
}
public long getId() {
return getLongField(ID);
}
public PersistentString getName() {
return getObjectField(NAME);
}
public PersistentString getDepartment() {
return getObjectField(DEPARTMENT);
}
public void setName(PersistentString name) {
setObjectField(NAME, name);
}
public void setDepartment(PersistentString department) {
setObjectField(DEPARTMENT, department);
}
public int hashCode() {
return Long.hashCode(getId());
}
public boolean equals(Object obj) {
if (!(obj instanceof Employee)) return false;
Employee emp = (Employee)obj;
return emp.getId() == getId() && emp.getName().equals(getName());
}
public String toString() {
return String.format("Employee(%d, %s)", getId(), getName());
}
}
The first thing you may notice by looking at this code is that it looks very similar to any regular class definition in Java. First, we have the class fields, defined as private (as well as static final, but more on that below). There are also two constructors. The first one, which builds a new persistent object from the parameters id, name and department, needs to pass its type definition (as an instance of ObjectType<Employee>) to its parent class PersistentObject (all custom persistent classes need to have this class as an ancestor in their inheritance path). The second constructor builds a new persistent object by copying itself from another employee object (p) passed as parameter. In this case, it is possible to just pass the whole object p to the parent class. Finally, we have the getters and setters and all the other public methods.
You may have also noticed the strange way in which fields are declared. Why are we not declaring ID as a regular long? Or NAME as a string? Also, why are fields declared as static final? The reason is that these are not fields in the traditional way, but meta fields. They only serve as a guidance to PersistentObject, which is going to access the real fields as offsets in persistent memory. They are declared as static final so we only have one copy of the meta fields for all the objects of the same class.
This need for meta fields is just an artifact of persistent objects not being supported natively in Java. PCJ uses meta fields to lay out persistent objects on the persistent heap and relies on the PMDK libraries for memory allocation and transaction support. Native code from PMDK libraries is called using the Java Native Interface (JNI). For a high-level overview of the implementation stack, see Figure 1.
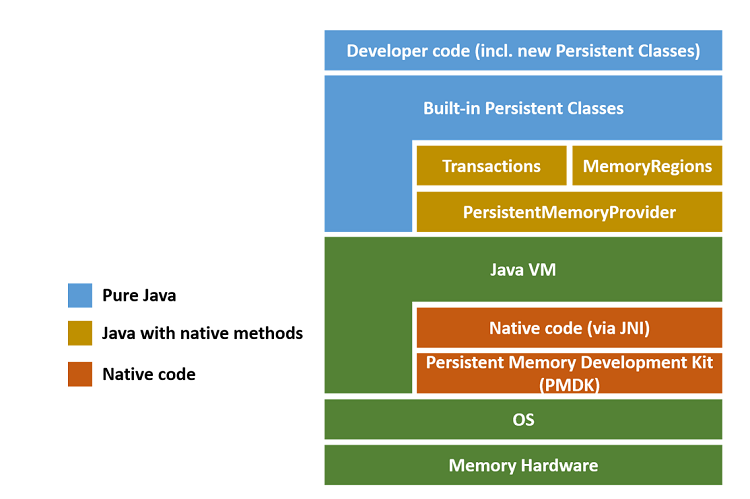
Figure 1. High-level overview of the Persistent Collections for Java* (PCJ) implementation stack.
I do not want to finish this section without talking about transactions. With PCJ, any modifications done to persistent fields through the provided accessor methods (such as setLongField() or setObjectField()) are automatically transactional. This means that if a power failure were to happen in the middle of a field write, changes would be rolled back (so data corruption, such as a torn write on a long string, would not happen). If atomicity for more than one field at a time is required, however, explicit transactions are needed. A detailed explanation of these transactions is out of the scope of this article. If you are interested in how transactions work in C/C++, you can read the following introduction to pmemobj transactions in C as well as the introduction to pmemobj transactions in C++.
The following snippet shows how PCJ transactions look:
...
Transaction.run(()->{
// transactional code
});
...
How to Run
If you download the sample from GitHub, a Makefile is provided which will download the latest versions of both PCJ as well as PMDK from their respective repositories. All you need is a C++ compiler (and, of course, Java) installed on your system. Nevertheless, I will show you here what steps you should follow in order to compile and run your persistent memory Java programs. For these, you need to have PMDK and PCJ installed on your system.
To compile the Java classes, you need to specify the PCJ class path. Assuming you have PCJ installed on your home directory, do the following:
$ javac -cp .:/home/<username>/pcj/target/classes Employee.java
$ javac -cp .:/home/<username>/pcj/target/classes EmployeeList.java
$
After that, you should see the generated *.class files. In order to run the main() method inside EmployeeList.class, you need to (again) pass the PCJ class path. You also need to set the java.library.path environment variable to the location of the compiled native library used as a bridge between PCJ and PMDK:
$ java -cp .:/…/pcj/target/classes -Djava.library.path=/…/pcj/target/cppbuild EmployeeListSummary
In this article, I presented an introduction to the Java API for persistent memory programming. This API emphasizes persistent collections, since collection classes map well to the use cases observed for many persistent memory applications. I showed how it is possible to instantiate and store a persistent collection (without serialization), as well as fetch it later after a power cycle. A full example, comprised of a persistent array of employees (being an Employee a custom persistent class implemented from scratch) is described in detail. I finalize the article by showing how Java programs using PCJ can be compiled and run.
About the Author
Eduardo Berrocal joined Intel as a Cloud Software Engineer in July 2017 after receiving his PhD in Computer Science from the Illinois Institute of Technology (IIT) in Chicago, Illinois. His doctoral research interests were focused on (but not limited to) data analytics and fault tolerance for high-performance computing. In the past he worked as a summer intern at Bell Labs (Nokia), as a research aide at Argonne National Laboratory, as a scientific programmer and web developer at the University of Chicago, and as an intern in the CESVIMA laboratory in Spain.
Resources
- The Non-Volatile Memory (NVM) Programming Model (NPM)
- The Persistent Memory Development Kit (PMDK)
- Python bindings for PMDK
- Persistent Collections for Java
- Find Your Leaked Persistent Memory Objects Using the Persistent Memory Development Kit (PMDK)
- How to emulate Persistent Memory
- The Java Native Interface (JNI)
- An introduction to pmemobj (part 2) – transactions
- C++ bindings for libpmemobj (part 6) – transactions
- Link to sample code in GitHub