| File(s): | Download |
| License: | BSD 3-clause |
| Optimized for... | |
|---|---|
| Operating System: | Linux* kernel version 4.3 or higher |
| Hardware: | Emulated: See How to Emulate Persistent Memory Using Dynamic Random-access Memory (DRAM) |
| Software: (Programming Language, tool, IDE, Framework) |
Intel® C++ Compiler, Persistent Memory Development Kit (PMDK) libraries |
| Prerequisites: | Familiarity with C++ |
Introduction
This article explores some basic Persistent Memory Development Kit (PMDK) building blocks, including persistent pointers, transactions, and persistent mutexes. A multithreaded example application that calculates the areas of a triangle and circle, along with the volumes of a cone and a sphere is included to help to illustrate PMDK concepts. Each thread performs calculations on each shape for a number of iterations. The goal is to demonstrate how a multithreaded C++ application can read and update data in different persistent-memory pools.
The example application uses the transactional features of libpmemobj, the object-oriented library in PMDK. Through the use of transactions and persistent-memory pools, data is protected from an unplanned interruption such as a power or application failure during a write. Transactions are atomic, meaning they either commit all changes or none. If a transaction is not fully committed, libpmemobj will roll back the changes to maintain data consistency. This avoids partial updates, also called torn writes, which are difficult for applications to detect and resolve. For more information about PMDK transactions, read C++ Transactions for Persistent Memory Programming. Persistent-memory pools are memory mapped files containing persistent objects within them. For more information on persistent memory pools, read An Introduction to Persistent Memory Pools in C++.
Prerequisites
The article assumes that you have a basic understanding of persistent memory concepts and are familiar with features of the PMDK. If not, visit the Intel® Developer Zone (Intel® DZ)'s Persistent Memory site, where you’ll find the information you need to get started.
Code Sample Design
Figure 1 below shows an overview of the sample code. The application uses two persistent-memory pools, pool1 and pool2. Each pool stores different classes of objects, with pool1 storing circle and sphere objects, and pool2 containing triangle and cone objects. The sample can run multiple threads, which compete for exclusive access to these objects in order to compute the shape areas and volumes with current data, or to change their values.
…
struct params {
pobj::pool<root> pop;
double height, r, base;
params(pobj::pool<root> pop,
double height,
double r, double base) : pop(pop), height(height), r(r), base(base)
{}
};
…
/* Triangle class */
…
void set_values(params* pdata)
{
pobj::transaction::exec_tx(pdata->pop, [&] {
if (radius > DIVISOR) {
radius = radius / DIVISOR;
height = height / DIVISOR;
cout << "\n Cone radius+height Reduce by " << DIVISOR << endl;
}
else {
radius = radius + pdata->base;
height = height + pdata->height;
}
}, pmutex);
}
/* Triangle class */
…
/* access_pool function */
…
void access_pool(int thread_id, int num_itr, pobj::pool<root> pop1,
pobj::persistent_ptr<root> pool1, pobj::pool<root> pop2,
pobj::persistent_ptr<root> pool2, double Rand_X)
{
int remainder = thread_id % 2;
for (int i = 0; i < num_itr; i++) { // Start For-loop
if (remainder == 0) { // Process EVEN threads
print_safe(1, thread_id, i, pool1, pool2);
params vars = params(pop1, (Rand_X * 2.0) + 10.0,(Rand_X * 2.0) + 88.76,(Rand_X * 2.0) + 16.19);
pool1->circle->set_values(&vars);
pool1->sphere->set_values(&vars);
}
else { // Process ODD threads
print_safe(2, thread_id, i, pool1, pool2);
params vars = params(pop2, (Rand_X * 6.0) + 32.0,(Rand_X * 6.0) + 43.76,(Rand_X * 6.0) + 51.19);
pool2->triangle->set_values(&vars);
pool2->cone->set_values(&vars);
}
} // End For-loop
} // End access_pool function…
/* access_pool function */
…
/* Main function*/
…
Rand_X = dis(gen); //Generate random numbers
threads[i] = thread(access_pool, i, num_itr, pop1, pool1, pop2, pool2, Rand_X);
…
/* Main function*/
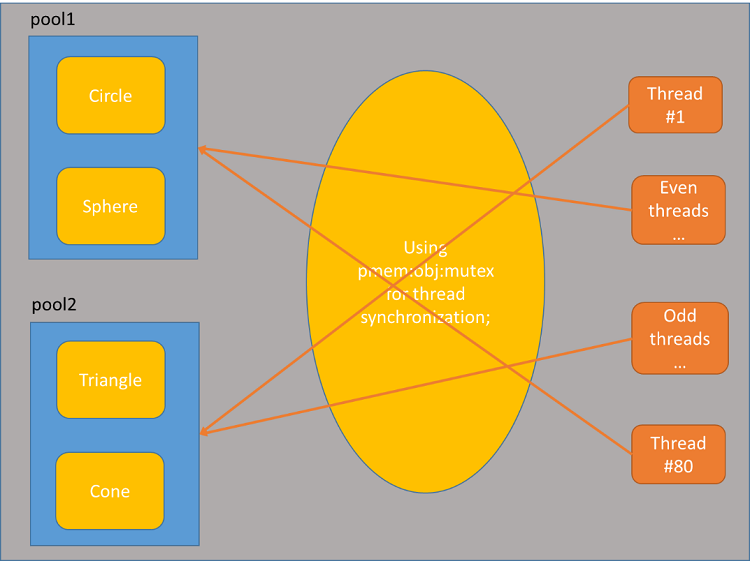
Figure 1. Overview of the threads accessing the two persistent-memory pools
Data Structures
As noted earlier, this program interacts with two persistent-memory pools, where each one has two different objects inside. Pool1 stores the Circle and Sphere objects and pool2 stores the Triangle and Cone objects. Due to the nature of virtual memory, pools may be mapped to different addresses during different program invocations. The library libpmemobj gives us a special object of class pool to interface with the mapped pools. Through this object (usually called pop, for persistent object pointer) we can get a valid pointer to the root object of the pool. Every pool has a single root object, which is needed in order to access all the other objects created in the pool. In the case of this sample, both pools’ root objects stores two pointers to the two objects created inside each pool. See Figure 2 for more details. The data structure for the presented sample code is shown in Figure 3.
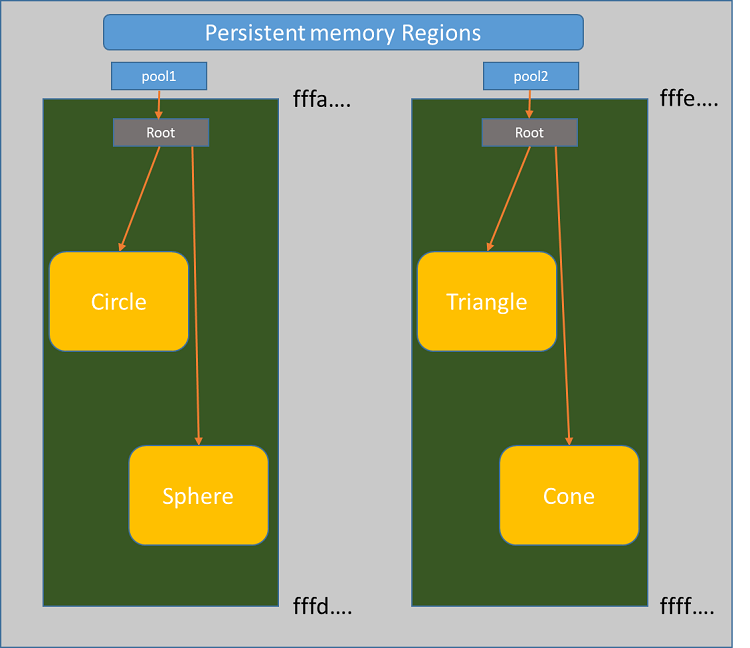
Figure 2. A visualized persistent-memory region showing the concept for the pools and persistent memories
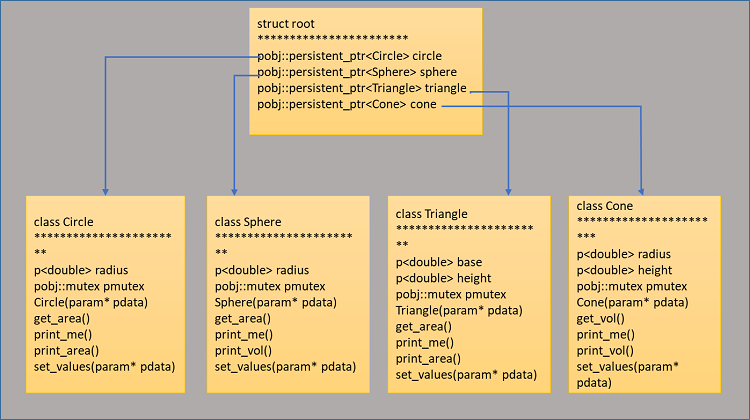
Figure 3. Data structure for the presented sample code
A Code Walk-through
Let’s take a look at how the code sample is structured. The program starts out by creating or opening the two persistent-memory pools and initializing the persistent objects within them. Threads will use these values to compute the areas of the circle and triangle, and the volumes of the sphere and cone. After a thread has finished computing the corresponding areas and volumes, the values of the objects are updated by multiplying them with a random number in the range from 1 to 100. Changing the values (height, base, and radius) adds a fun twist to this code sample. Given the race condition occurring between threads in this sample, some of them will compute the same areas and volumes. This race condition is by design, since accessing the data to calculate areas or volumes use a different locked region than updating the data. However, data access for both reads and writes is synchronized, as we will see next, so no persistent corruption can ever happen. You can see the output of the execution of this sample in Figure 4.
The syntax for pool creation is shown below. For more information about persistent memory pools in libpmemobj, refer to the article "C++ bindings for libpmemobj (part 4) - pool handle wrapper". Before we create the pool, we check whether the pools passed as parameters exist. If they do not exist, we create them with the create function. The create function requires four parameters:
(1) PERS_MEM_POOL1 – the location of the memory-pool file
(2) LAYOUT – the name for the object layout in the pool
(3) POOLSIZE – the size of the pool
(4) S_IRUSR|S_IWUSR – defined as read/write permission access to the memory pool file
Below is an example for pool1. The code for pool2 has the same syntax:
pool1:
…
pers_mem_pool1 = pool<root>::create(PERS_MEM_POOL1, LAYOUT, POOLSIZE, S_IRUSR|S_IWUSR);
…
If the pools exist, we open them using the open function which requires two parameters:
- PERS_MEM_POOL1 – the location of the memory pool file
- LAYOUT – the name for the object layout in the pool
…
pop1 = pobj::pool<root>::open(PERS_MEM_POOL1, LAYOUT1);
pool1 = pop1.get_root();
…
Once the pools are opened, both pool objects represent memory-mapped files within the application. If the pools have just been created, the application allocates new persistent objects by calling the libpmemobj function make_persistent(). On the other hand, if the application opens existing memory pools, the application begins accessing the data normally.
Calls to make_persistent() must always be done within a transaction. In this case, we call make_persistent() inside main() as shown below. For more information, you can read C++ bindings for libpmemobj (part 6) - transactions and C++ bindings for libpmemobj (part 5) - make_persistent at pmem.io. We assign the address of the newly allocated persistent objects to the persistent pointer variables inside the corresponding root objects. See the code snippet below for more details:
…
pobj::transaction::exec_tx(pool1, [&] {
pool1->circle = pobj::make_persistent<Circle>(&vars);
pool1->sphere = pobj::make_persistent<Sphere>(&vars);
});
…
pobj::transaction::exec_tx(pool2, [&] {
pool2->triangle = pobj::make_persistent<Triangle>(&vars);
pool2->cone = pobj::make_persistent<Cone>(&vars);
});
…
During transactions, pool1 and pool2 are used to access and modify the objects in each of the corresponding pools. Embedded inside the transaction execution statement, the values inside the structure params are used by the constructors to initialize the persistent memory objects. The transaction block of code will ensure that all items are updated as one unit of work inside persistent memory. This means that all changes done inside an unfinished transaction will be rolled back in case of an interruption such as a power failure.
In persistent memory programming, we need to ensure that our written data is stored all the way to the memory device before we can say that it is persistent. If it is not, recent writes may still sit unflushed in the CPU caches. In case of a power failure, unflushed data will be lost. To prevent this, we need to flush the data out of the caches. In the sample code below, the transaction statement is introduced. With transactions, flushing is done implicitly when the transaction ends.
…
Circle(params* pdata)
{
pobj::transaction::exec_tx(pdata->pop, [&] {
radius = pdata->r; // 8 bytes only
}, pmutex);
}
…
Triangle(params* pdata)
{
pobj::transaction::exec_tx(pdata->pop, [&] {
base = pdata->base;
height = pdata->height;
}, pmutex);
}
…
Cone(params* pdata)
{
pobj::transaction::exec_tx(pdata->pop, [&] {
radius = pdata->r;
height = pdata->height;
}, pmutex);
}
…
Sphere(params* pdata)
{
pobj::transaction::exec_tx(pdata->pop, [&] {
radius = pdata->r; // 8 bytes only
}, pmutex);
}
…
Multithreading
Next we’ll look at threads and synchronization. You saw that we used a persistent mutex above to lock the transaction. The transaction saves us from corrupting the data not only in case of a power failure but also in case of multiple threads writing to the same object. In this case, we are using a special persistent mutex (pmem::obj::mutex) rather than a standard one (std::mutex). This is because we can safely store a persistent mutex in persistent memory while using a standard one can result in a permanent deadlock. You can read the following introductory article about libpmemobj synchronization primitives for more information.
The sample also uses std::lock_guard for those functions that are not required to be persistent but need to be synchronized, such as the print_area() and print_volume() functions. Using std::lock_guard ensures that each thread is locked until the end of the code block. The syntax for lock_guard is demonstrated in the print_safe() function:
…
void print_safe(int pool_id, int thread_id, int num_itr, pobj::persistent_ptr<root> pool1,
pobj::persistent_ptr<root> pool2)
{
std::lock_guard<std::mutex> lock(print_mutex); // thread safe
if (pool_id == 1) { //access pool1
print_mesg(pool_id, thread_id, num_itr);
pool1->circle->print_area();
print_mesg(pool_id, thread_id, num_itr);
pool1->sphere->print_vol();
} else { //access pool2
print_mesg(pool_id, thread_id, num_itr);
pool2->triangle->print_area();
print_mesg(pool_id, thread_id, num_itr);
pool2->cone->print_vol();
}
}
…
}
…
Managing Threads
To manage threads, we use the combination of std::thread() and std::join() functions to create and join up to num_threads in two simple for loops as shown below:
…
/* Threading */
for (int i=0; i < num_threads; i++) {
Rand_X = dis(gen); //Generate random numbers
threads[i] = thread (access_pool, i, pers_mem1, pers_mem_pool1,
pers_mem2, pers_mem_pool2, Rand_X);
}
/* Join Threads */
for (int i = 0; i < num_threads; i++) {
threads[i].join ();
}
…
Inside the "Threading" for loop, we generate a random number for the bit of fun mentioned earlier. The thread() function passes the control over to the access_pool() function along with the all the persistent memory objects, thread number, and random number to access the persistent-memory pools.
The access_pool() function accesses the pools in order to compute and print out the area and volume results and then changes the values for every iteration. Each thread will run through this cycle num_itr (input from the command line) times.
Compile and Run
A Makefile is included to help with compiling and building the binary. A simple ‘make’ should compile it in the current working directory:
$make
For manual compilation:
$g++ -c pPool.cpp -o pPool.o -I. -std=c++11 nodebug –lpmem –lpmemobj –lpthread
After building the binary, the code sample can be run with the following statement:
$./pPool pool1 pool2 80 30
Below is an example of the result output:
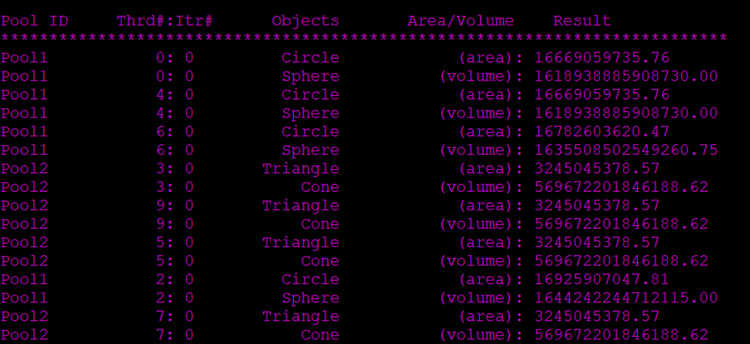

Figure 4. Result screen showing each thread accessing two different persistent-memory pools
On the results screen, you can see that each thread accesses a persistent-memory pool. Also, each thread runs multiple times depending on the value of num_itr. The results screen in Figure 4, shows the pool id, thread number, iteration number, object in the pools, computation for the area/volume, and finally the result.
Summary
In this article, we created and walked through a C++ sample application that demonstrates using persistent-memory pools, pointers, and transactions features of the PMDK library libpmemobj. We also introduced the transaction statement as a way to guarantee data atomicity to prevent data loss or corruption in case of power failure or application crash. The libpmemobj library is simple and easy to integrate to your existing code. The code sample is included with this article so that you can build and run the program yourself. You can find more persistent memory programming examples in the PMDK examples repository on our GitHub* repository
About the Author
Thai Le is a software engineer focusing on persistent memory programming in the Core Visual Computing Group at Intel Corporation.
References
- How to Emulate Persistent Memory Using Dynamic Random-access Memory (DRAM)
- pmem.io. PMDK | The libpmemobj Library
- pmem.io: An introduction to pmemobj (part1) – accessing the persistent memory
- pmem.io: C++ bindings for libpmemobj (part 5) - make_persistent
- pmem.io: C++ bindings for libpmemobj (part 6) - transactions
- Persistent Memory Library
- Introduction to Programming with Persistent Memory from Intel
- Persistent Memory - Get Started