Intel® oneAPI Threading Building Blocks Developer Guide and API Reference
A newer version of this document is available. Customers should click here to go to the newest version.
Visible to Intel only — GUID: GUID-ACBEC992-7FF7-4E5F-A9D4-628630CA69FA
Visible to Intel only — GUID: GUID-ACBEC992-7FF7-4E5F-A9D4-628630CA69FA
Data Flow Graph
In a data flow graph, nodes are computations that send and receive data messages. Some nodes may only send messages, others may only receive messages, and others may send messages in response to messages that they receive.
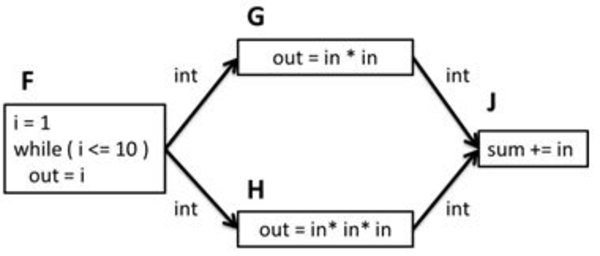
In the following data flow graph, the left-most node generates the integer values from 1 to 10 and passes them to two successor nodes. One of the successors squares each value it receives and passes the result downstream. The second successor cubes each value it receives and passes the result downstream. The right-most node receives values from both of the middle nodes. As it receives each value, it adds it to a running sum of values. When the application is run to completion, the value of sum will be equal to the sum of the sequence of squares and cubes from 1 to 10.
Simple Data Flow Graph
The following code snippet shows an implementation of the Simple Data Flow Graph shown above:
int sum = 0;
graph g;
function_node< int, int > squarer( g, unlimited, [](const int &v) {
return v*v;
} );
function_node< int, int > cuber( g, unlimited, [](const int &v) {
return v*v*v;
} );
function_node< int, int > summer( g, 1, [&](const int &v ) -> int {
return sum += v;
} );
make_edge( squarer, summer );
make_edge( cuber, summer );
for ( int i = 1; i <= 10; ++i ) {
squarer.try_put(i);
cuber.try_put(i);
}
g.wait_for_all();
cout << "Sum is " << sum << "\n";
In the implementation above, the following function_nodes are created:
one to square values
one to cube values
one to add values to the global sum
Since the squarer and cuber nodes are side-effect free, they are created with an unlimited concurrency. The summer node updates the sum through a reference to a global variable and therefore is not safe to execute in parallel. It is therefore created with a concurrency limit of 1. The node F from Simple Data Flow Graph above is implemented as a loop that puts messages to both the squarer and cuber node.
A slight improvement over the first implementation is to introduce an additional node type, a broadcast_node. A broadcast_node broadcasts any message it receives to all of its successors.
This enables replacing the two try_put’s in the loop with a single try_put:
broadcast_node<int> b(g);
make_edge( b, squarer );
make_edge( b, cuber );
for ( int i = 1; i <= 10; ++i ) {
b.try_put(i);
}
g.wait_for_all();
An even better option, which will make the implementation even more like the Simple Data Flow Graph above, is to introduce an input_node. An input_node, as the name implies only sends messages and does not receive messages. Its constructor takes two arguments:
template< typename Body > input_node( graph &g, Body body)
The body is a function object, or lambda expression, that contains a function operator:
Output Body::operator()( oneapi::tbb::flow_control &fc );
You can replace the loop in the example with an input_node
input_node< int > src( g, src_body(10) ); make_edge( src, squarer ); make_edge( src, cuber ); src.activate(); g.wait_for_all();
The runtime library will repeatedly invoke the function operator in src_body until fc.stop() is invoked inside the body. You therefore need to create body that will act like the body of the loop in the Simple Data Flow Graph above. The final implementation after all of these changes is shown below:
class src_body {
const int my_limit;
int my_next_value;
public:
src_body(int l) : my_limit(l), my_next_value(1) {}
int operator()( oneapi::tbb::flow_control& fc ) {
if ( my_next_value <= my_limit ) {
return my_next_value++;
} else {
fc.stop();
return int();
}
}
};
int main() {
int sum = 0;
graph g;
function_node< int, int > squarer( g, unlimited, [](const int &v) {
return v*v;
} );
function_node< int, int > cuber( g, unlimited, [](const int &v) {
return v*v*v;
} );
function_node< int, int > summer( g, 1, [&](const int &v ) -> int {
return sum += v;
} );
make_edge( squarer, summer );
make_edge( cuber, summer );
input_node< int > src( g, src_body(10) );
make_edge( src, squarer );
make_edge( src, cuber );
src.activate();
g.wait_for_all();
cout << "Sum is " << sum << "\n";
}
This final implementation has all of the nodes and edges from the Simple Data Flow Graph above. In this simple example, there is not much advantage in using an input_node over an explicit loop. But, because an input_node is able to react to the behavior of downstream nodes, it can limit memory use in more complex graphs. For more information, see:ref:create_token_based_system .