
In modern data centers, we have seen a wide range of applications involving intensive memory operations and transformations, such as memcpy(), memmove(), hashing, and compression. These applications include, but are not limited to, database, image processing and video transport, and graph processing. In addition, such memory operations and transformations are also common in a data center’s infrastructure software, consuming a significant amount of CPU cycles. This is also known as the “data center tax” because these cycles could have been used to run applications. Ideally, such operations should be offloaded to optimized hardware engines.
Intel® Data Streaming Accelerator
Intel Data Streaming Accelerator (Intel® DSA) is a high-performance data copy and transformation accelerator integrated in the latest 4th Generation Intel® Xeon® Scalable processors. It provides not only processing efficiency and practicality, but also versatility. Intel DSA is equipped with hardware components to efficiently process work descriptors submitted by one or more users. Through the support of shared virtual memory (SVM), these work descriptors can be submitted by user applications directly to Intel DSA via memory-mapped I/O (MMIO) registers, and the target memory regions are not required to be pinned in the operating system. Users are also allowed to directly configure the underlying computational resources based on their needs, which is enabled by the user interfaces provided by a set of dedicated drivers. In addition, Intel DSA provides better functionality by means of newly supported operations (Table 1). Therefore, it is expected that more user/kernel processes can take advantage of what Intel DSA offers.
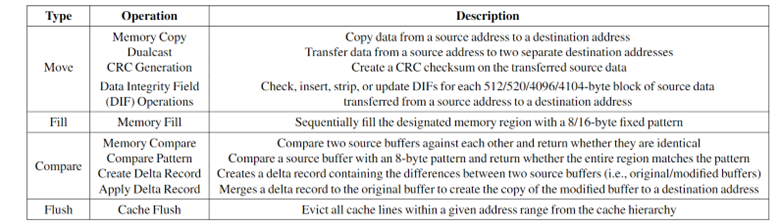
Table 1. Data streaming operations supported by Intel® DSA
Intel® Data Accelerator Driver (IDXD) is a kernel mode driver for device initialization and management. It provides functionality for Intel DSA discovery, initialization, and configuration. Applications can leverage the user-space libaccel-config API library for such control operations. For the data path, to provide low-latency access to the Intel DSA instance for applications, IDXD exposes the MMIO portals as a char device via mmap(). Given all these new features and improvements, we see significant performance gains of Intel DSA over its software counterparts in multiple domains (Table 2) and on multiple operations, especially with medium-to-large data size (Figure 1).
|
Area |
Example Applications and Operations |
|---|---|
|
Networking stack acceleration |
DPDK, software virtual switch, video transport |
|
Storage stack acceleration |
SPDK, NVMe-oF, DAOS |
|
Data center tax reduction |
VM boot-up/migration, memory compaction |
|
HPC/ML acceleration |
Memory movement/zeroing in libfabric/MPI |
|
Heterogeneous memory management acceleration |
Page migration for CXL/Pmem-based tiered memory systems |
Table 2. Potential Intel® DSA usage in multiple domains
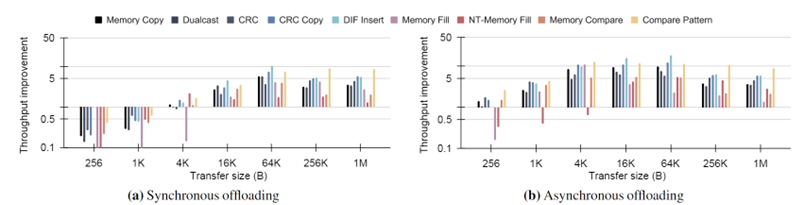
Figure 1. Throughput improvements of data streaming operations over their software counterparts with varying transfer sizes (batch size: 1); Memory Fill and NT-Memory Fill refer to allocating and non-allocating writes (similar to regular store and nt-store), respectively
Operating Intel DSA
Like other accelerators, Intel DSA employs descriptors and work queues (WQ) to interact with the CPU software (Figure 2).
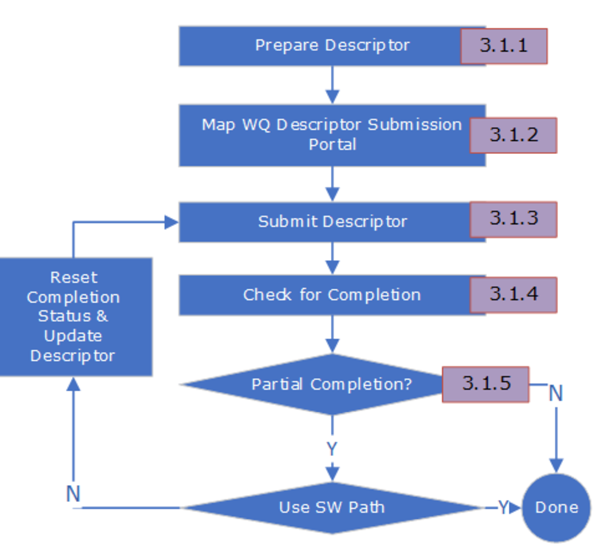
Figure 2. Descriptor processing sequence
Data movement is the most common use-case of Intel DSA, so we will use a data-copy example to demonstrate usage. Suppose in a key-value store application, where we have large key-value pair size, every time we retrieve or update the value of a given key, memory copy will happen and incur lots of CPU cycles. We would rather offload these operations to Intel DSA. Assuming the Intel DSA instance has been enumerated and configured by tools like accel-config, the programmer first needs to allocate and fill the descriptor data structure (Figure 3). The descriptor contains information about the desired operation, such as operation type, source and destination address, data length, etc.
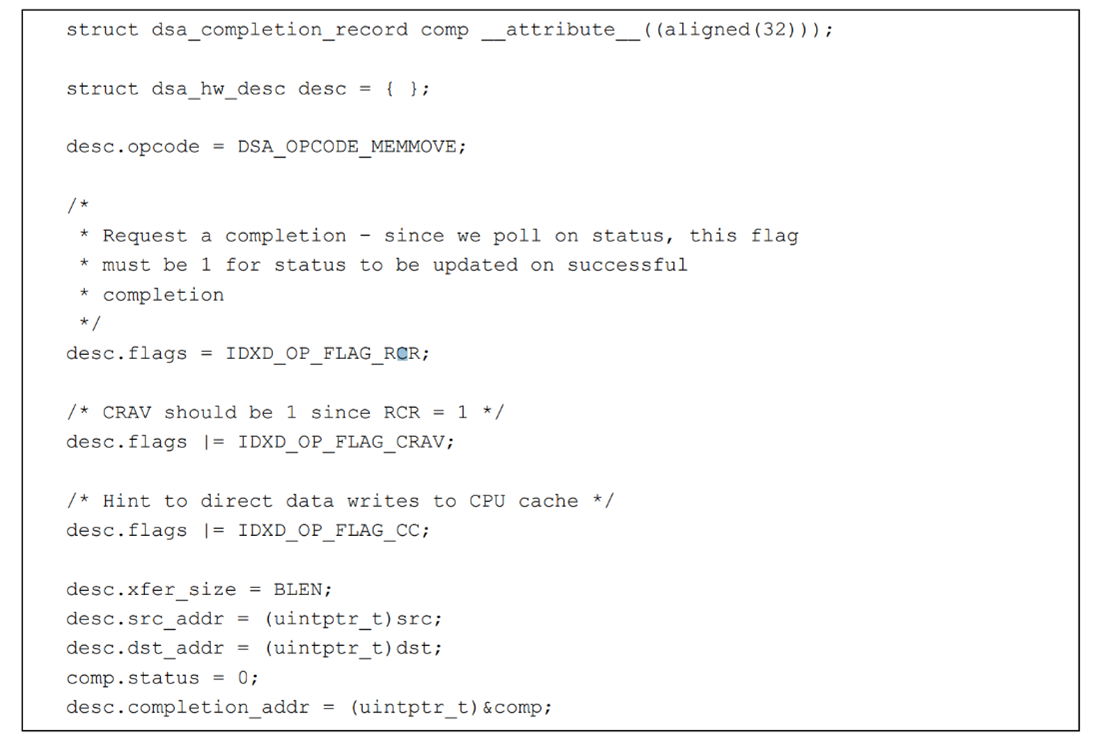
Figure 3. Descriptor initialization
Having the descriptor ready, the next step for the programmer is to submit the descriptor to a WQ opened and mapped in the current program. Depending on the WQ type, the software may use either the ENQCMD or MOVDIR64B instruction for descriptor submission. Both instructions are supported in GNU GCC (version 10 and later), and the programmer can use the x86 intrinsics to call them (Figure 4).

Figure 4. Descriptor submission
To check the completion of the descriptor, the programmer needs to poll the status field of the completion record, which will be updated by Intel DSA. The most common way of doing this is spin-polling (Figure 5). New instructions, like PAUSE and UMONITOR/UMWAIT, can be applied to further reduce the processor’s power consumption, as the core can enter a different power state with such instructions. (See the Intel® 64 and IA-32 Architectures Software Developer Manuals for more information.)

Figure 5. Checking descriptor completion
Take Advantage of Intel DSA with Software Libraries
The Intel® Data Mover Library (Intel® DML) and Intel® DSA Transparent Offload Library (Intel® DTO) make Intel DSA easier to use. Intel DML provides a set of high-level C/C++ APIs for data movement and transformation, calling the underlying Intel DSA unit when available. It supports advanced capabilities (all Intel DSA hardware operations, asynchronous offload, load balancing, etc.). Intel DML v1.0.0 is available on GitHub. After cloning the repository and installing the required packages, it can be compiled and installed by simple CMake commands (see the Intel DML Documentation for more installation options):
Figure 6 demonstrates basic usage of Intel DML. While the basic steps remain unchanged, more details are hidden by Intel DML APIs and abstraction. Continuing the example of key-value store application, instead of manually preparing and submitting the descriptor, the programmer can call Intel DML so that the designated memory copy is offloaded to Intel DSA.

Figure 6. Example of basic data movement with Intel® DML
Intel DTO is a less-intrusive library that allows the application to leverage Intel DSA transparently without source code modification. Users can either dynamically link the library using the ‑ldto and ‑laccel‑config linker options or preload the library via LD_PRELOAD without having to recompile their application. When common system API calls like memmove(), memcpy(), memset(), or memcmp() are used, they are intercepted and replaced by Intel DTO functions to access the corresponding synchronous Intel DSA operations.
In addition to Intel DML and Intel DTO, which are general-purpose libraries, there are also domain-specific software libraries that take advantage of Intel DSA. For example, in the Data Plane Development Kit (DPDK) for high-performance kernel-bypass network programming, Intel DSA, along with DMA engines from other vendors, has been abstracted and wrapped in the dmadev library. Users can call the corresponding APIs to offload network packets copying to Intel DSA instances. Similarly, the Storage Performance Development Kit (SPDK) has Intel DSA support in its /lib/accel library to support various operations offloading. Intel DSA has also been enabled in HPC libraries, such as libfabric and MPI, which are used in not only traditional scientific computing workloads, but also emerging distributed ML/AI applications.
Make the Most Out of Intel DSA
As an on-chip accelerator for streaming data, Intel DSA benefits from proper tuning of the programming models for optimal performance. Based on our experiences, we summarize a number of guidelines and recommendations for using Intel DSA. (See this technical report for more details.)
Keep a Balanced Batch Size and Transfer Size
Offloading work of a certain size to Intel DSA can be done using either one descriptor for the full memory region or batching multiple smaller descriptors for the same aggregate size. The general trend indicates a decrease in throughput when using larger batches for the same offloaded work. As individual descriptors must be processed internally in Intel DSA and read the corresponding data from memory, the additional overhead for managing the increased number of descriptors may reduce the effective throughput achieved from these operations. If the desired data for offloading is contiguous, coalescing into a larger, single descriptor of the equivalent size may improve both throughput and latency.
When offloading synchronously, a weak pattern emerges, showing an optimum point in throughput between maximizing batches and maximizing transfer size. Modestly batching the work (4-8 descriptors) yields the best results. This is due to balancing the latency from fetching sequential regions of memory and processing batched descriptors.
Use Intel DSA Asynchronously When Possible
Offloading operations to Intel DSA in an asynchronous manner provides optimal efficiency and performance for both the CPU core and Intel DSA hardware. This can use Intel DML for easy implementation. When limited in asynchronous potential, transfer sizes below 4 KB should be used on the CPU core if cache pollution is acceptable. As an on-chip accelerator, Intel DSA brings more options to interact with the cache and (heterogeneous) memory hierarchy.
Control the Data Destination Wisely
Unlike the completion record that is always directed to the LLC, data written to the destination address of a descriptor can be steered either to the LLC or to the main memory. Intel DSA facilitates this cache control feature by allowing users to provide a hint (i.e., setting the cache control flag of a work descriptor) that notes the preferred destination. If the flag is set to 0, the data is written to the memory while invalidating the corresponding cache lines in the LLC, if any. If the flag is set to 1, the data is directly written to the LLC by allocating the corresponding cache lines. The underlying principle of this technique is identical to that of Intel® Data Direct I/O Technology (Intel® DDIO), a direct cache access (DCA) scheme leveraging the LLC as the intermediate buffer between the processor and I/O devices. In general, DDIO improves system performance by reducing the data access latency and reducing memory bandwidth pressure. However, one should be careful when using this feature because it can sometimes cause interference in the LLC.
Cache pollution negatively affects processes that share limited hardware resources. In many data center workloads, the latency gained from antagonistic background cache evictions may undermine the competitive service level agreements (SLAs) set for the primary applications. On the other hand, writing data that is either critical to performance or used by the core in the near future directly to the cache will provide an access latency and throughput advantage for the application. The programmer should wisely choose the data destination based on the application behavior.
Intel DSA as a Good Candidate of Moving Data across a Heterogeneous Memory System
Moving data to/from different memory mediums, such as NUMA remote memory, persistent memory, and CXL-based memory, is common in modern tiered memory systems. Intel DSA offers a high degree of configuration flexibility through the available hardware resources. Taking advantage of such configurations can yield optimal Intel DSA hardware utilization, and thus better performance.
Leverage Processing Engine-Level Parallelism
The number of processing engines used in a group can impact the maximum observed throughput. Increasing the number of processing engines per group improves throughput. Users should be aware of the common transfer size of offloaded tasks to these groups as smaller transfer sizes yield greater performance scaling.
Optimize WQ Configuration
Using batching or dedicated WQs (DWQs) provides greater benefits compared to a shared WQ (SWQ). Unless the shared WQ is used by many other threads, greater utilization and throughput can be achieved through reconfiguring to using more DWQs. SWQs may perform worse when few threads are used, but can outperform all configurations when using more threads than the total number of WQs, as that offloads concurrency management to hardware. Additionally, WQs can be configured to either shared or dedicated for providing performance isolation between WQs within a group. As Intel DSA has limited WQ entries, assigning 32 entries for a single WQ can provide almost the maximum throughput possible.
Conclusion
Intel DSA, as well as other on-chip accelerators appearing in the 4th Generation Intel Xeon Scalable processors, has the potential to reduce the data center tax and total cost of ownership. This article provides a high-level overview of Intel DSA and its fundamental usages, as well as several guidelines to make the most out of this accelerator. With a growing software ecosystem, we believe Intel DSA will be adopted for many data center workloads. Intel, in active collaboration with the open-source community, has been building and enabling this ecosystem.