FPGAi
Learn how FPGAs revolutionize AI applications with custom hardware acceleration, low latency, and energy efficiency.
Leading a New Era in AI with Altera FPGAs
Fusion of FPGAs and AI is not just an evolution—it's a revolution. Altera, an Intel company, is at the forefront of this revolution delivering the highest performance FPGA fabric enhanced and infused with AI tools and capabilities in this new era of FPGAi – a tight coupling of programmable logic and artificial intelligence capabilities to enable innovators to easily add intelligence to new custom solutions. This fusion enables intelligence to be added to innovative solutions empowering systems to make autonomous decisions, adapt to new data in real-time, or process information with unprecedented speed and efficiency. This is a giant step forward, offering dynamic, intelligent solutions that are ready to conquer the complexities faced in the next generation of solutions.
Solution Capability: High-Performance FPGAs
The Agilex family of high-performance FPGAs deliver the solution capabilities needed to accelerate innovators in the new era of FPGAi. With 2x better performance per watt vs. competing 7nm FPGAs, users can meet the demanding needs for lower power.
The Agilex 7 M-series includes up to 32 GB of HBM memory which alleviates bottlenecks for memory bound AI solutions like Large Language Models.
The Agilex 5 family contains the only FPGA fabric infused with AI making it ideal for compute bound AI networks such as CNNs. This family incorporates DSP with AI Tensor Blocks to vastly improve the amount of compute available. This mid-range family, with up to 56 INT8 TOPs, is well suited for the needs of low power embedded edge solutions.
Agilex FPGAs not only exemplify Altera's technological prowess but also redefine efficiency and transformative approaches to address the complexities of today's data-driven world.
Developer Usability: Common RTL + IP Flow
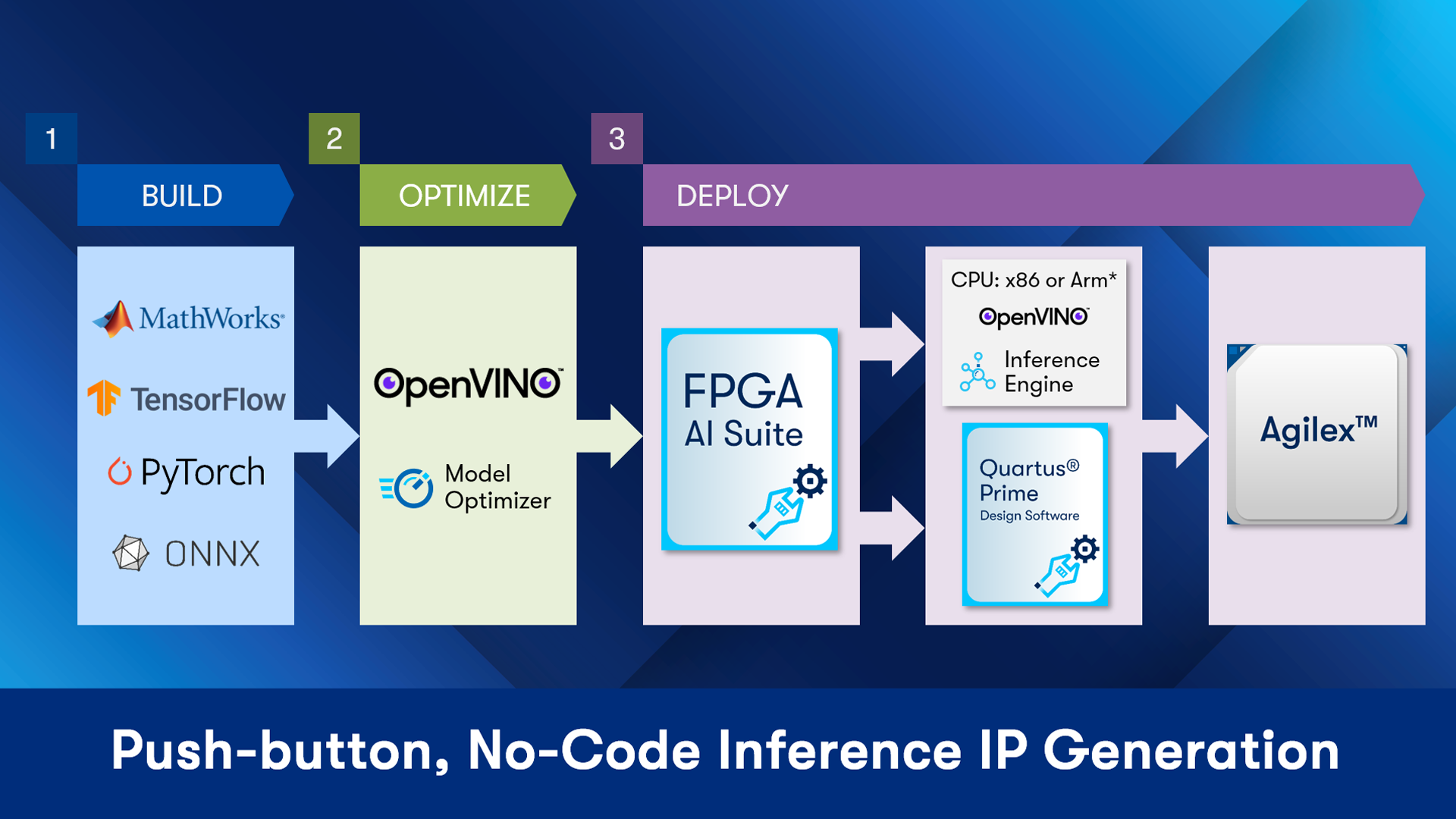
FPGA AI Suite is the linchpin of Altera’s FPGAi strategy, offering a seamless flow for embedding AI inference into Altera FPGAs. This suite takes advantage of the traditional RTL and IP flow and amplifies the intrinsic benefits of FPGAs—like reconfigurability and superior I/O management, allowing for the creation of real-time, low-latency AI applications without sacrificing power efficiency.
{kind=link}
The integration process is intuitive, enabling the addition of AI capabilities with the ease of adding IP. Emphasizing developer usability, FPGA AI Suite integration with Intel Quartus Prime Software and Platform Designer simplifies the integration of AI inference IP, making the development process more accessible and less time-consuming. It bridges the gap from AI model development to FPGA deployment, ensuring compatibility with leading frameworks such as TensorFlow and PyTorch through the OpenVINO toolkit. By tailoring deep learning models for our hardware, FPGA AI Suite empowers developers to fully leverage the power of FPGAi, fusing the speed of AI with the flexibility of FPGAs.
Workload Agility: AI that needs flexibility
Altera FPGAs, with their inherent ability to be reprogrammed on-the-fly, offers a canvas for continuous AI innovation, allowing engineers to tailor solutions to emerging challenges. This reconfigurability is further extended with support for a diverse set of I/O protocols enables workload agility – the ability to efficiently handle a diverse array of applications from real-time data processing to AI-driven analytics without costly redesign.
Moreover, the extensibility of FPGAi is evident in its capacity to integrate with existing systems and future technologies, ensuring a sustainable approach to development that values longevity. By leveraging this power, industries can confidently stride towards a future where their technological investments are not only intelligent but also responsible and enduring. Agility, flexibility, extensibility, sustainability, and longevity are what set FPGAi apart in the AI revolution, promising a smarter and more adaptable world.
FPGAi Applications
Edge AI
FPGAs are especially suited for edge AI in a wide range of applications across industrial, medical, test and measurement, aerospace, defense, and automotive. Data at the edge can be diverse, ranging from images, vibration sensors, and radar data to pressure sensors. Diverse I/O protocols, low latency, low power, and long lifetime are additional FPGA advantages at the edge.
Network
The network facilitates data transfers and communication between edge devices, cloud services, and other interconnected components. FPGAs are specially equipped with the latest generation of high-speed I/O standards to facilitate usage in wireless and wireline networking. As networks begin to add intelligence for various emerging applications, such as anomaly detection, wireless channel estimation, and wireless decoder convergence, FPGAs can play an effective role.
Cloud/Data Center/High Performance Computing
FPGAs have been widely deployed in cloud and data center environments to accelerate a wide range of workloads, including databases, genomics, and networking. The intrinsic advantages of FPGAs help AI inference tasks, such as large language models, conversational AI, and recommendation systems. Other FPGA neural network applications include anomaly detection at very high data rates in NICs, financial fraud detection, and high-speed trading. In addition, the high energy efficiency of FPGAs helps mitigate cooling costs and supports the development of greener AI technologies.
Watch the video about Myrtle.ai's turnkey software application VOLLO for low-latency inference ›
Read the solution brief about a new approach to Neuromorphic Computing ›
Explore Resources to Get You Started
Intel® FPGA AI Suite
Speed up your FPGA development for AI inference using frameworks such as TensorFlow or PyTorch and OpenVINO toolkit, while leveraging robust and proven FPGA development flows with the Intel Quartus Prime Software.
Learn more
Intel® Distribution of OpenVINO Toolkit
An open-source toolkit that makes it easier to write once and deploy anywhere.
Learn more
Need More Information?
Let us know how we can help with your questions.
Contact us
Discover More AI Resources
Why FPGAs Are Good for Implementing Edge AI and Machine Learning Applications
Read the emerging use cases of FPGA-based AI inference in the edge and custom AI applications and Intel’s software and hardware solutions for edge FPGA AI.
FPGA Vs. GPU for Deep Learning
While no single architecture works best for all machine and deep learning applications, FPGAs can offer distinct advantages over GPUs and other types of hardware.
Quantized Neural Networks for FPGA Inference
Low-precision quantization for neural networks supports AI application specifications by providing greater throughput for the same footprint or reducing resource usage.
Partners Accelerating AI at the Edge
Watch these videos to learn how Altera’s partners can help you accelerate AI workloads on FPGAs.