Visible to Intel only — GUID: cut1573320429345
Ixiasoft
1. Intel® HLS Compiler Pro Edition Reference Manual
2. Compiler
3. C Language and Library Support
4. Component Interfaces
5. Component Memories (Memory Attributes)
6. Loops in Components
7. Component Concurrency
8. Arbitrary Precision Math Support
9. Component Target Frequency
10. Systems of Tasks
11. Libraries
12. Advanced Hardware Synthesis Controls
13. Intel® High Level Synthesis Compiler Pro Edition Reference Summary
A. Advanced Math Source Code Libraries
B. Supported Math Functions
C. Cyclone® V Restrictions
D. Intel® HLS Compiler Pro Edition Reference Manual Archives
E. Document Revision History of the Intel® HLS Compiler Pro Edition Reference Manual
6.1. Loop Initiation Interval (ii Pragma)
6.2. Loop-Carried Dependencies (ivdep Pragma)
6.3. Loop Coalescing (loop_coalesce Pragma)
6.4. Loop Unrolling (unroll Pragma)
6.5. Loop Concurrency (max_concurrency Pragma)
6.6. Loop Iteration Speculation (speculated_iterations Pragma)
6.7. Loop Pipelining Control (disable_loop_pipelining Pragma)
6.8. Loop Interleaving Control (max_interleaving Pragma)
6.9. Loop Fusion
11.4.1.1. Integration of an RTL Module into the HLS Pipeline
11.4.1.2. RTL Module Interfaces
11.4.1.3. RTL Reset and Clock Signals
11.4.1.4. Object Manifest File Syntax
11.4.1.5. Mapping HLS Data Types to RTL Signals
11.4.1.6. HLS Emulation Models for RTL-Based Functions
11.4.1.7. Potential Incompatibility between RTL Modules and Partial Reconfiguration
11.4.1.8. Stall-Free RTL
11.4.1.9. RTL Module Restrictions and Limitations for HLS Libraries
13.1. Intel® HLS Compiler Pro Edition i++ Command-Line Arguments
13.2. Intel® HLS Compiler Pro Edition Header Files
13.3. Intel® HLS Compiler Pro Edition Compiler-Defined Preprocessor Macros
13.4. Intel® HLS Compiler Pro Edition Keywords
13.5. Intel® HLS Compiler Pro Edition Simulation API (Testbench Only)
13.6. Intel® HLS Compiler Pro Edition Component Memory Attributes
13.7. Intel® HLS Compiler Pro Edition Loop Pragmas
13.8. Intel® HLS Compiler Pro Edition Scope Pragmas
13.9. Intel® HLS Compiler Pro Edition Component Attributes
13.10. Intel® HLS Compiler Pro Edition Component Default Interfaces
13.11. Intel® HLS Compiler Pro Edition Component Invocation Interface Control Attributes
13.12. Intel® HLS Compiler Pro Edition Component Macros
13.13. Intel® HLS Compiler Pro Edition Systems of Tasks API
13.14. Intel® HLS Compiler Pro Edition Pipes API
13.15. Intel® HLS Compiler Pro Edition Streaming Input Interfaces
13.16. Intel® HLS Compiler Pro Edition Streaming Output Interfaces
13.17. Intel® HLS Compiler Pro Edition Memory-Mapped Interfaces
13.18. Intel® HLS Compiler Pro Edition Load-Store Unit Control
13.19. Intel® HLS Compiler Pro Edition Arbitrary Precision Data Types
B.1. Math Functions Provided by the math.h Header File
B.2. Math Functions Provided by the extendedmath.h Header File
B.3. Math Functions Provided by the ac_fixed_math.h Header File
B.4. Math Functions Provided by the hls_float.h Header File
B.5. Math Functions Provided by the hls_float_math.h Header File
B.6. Default Rounding Schemes and Subnormal Number Support
Visible to Intel only — GUID: cut1573320429345
Ixiasoft
4.4.3.1. Load-Store Unit Types
The Intel® HLS Compiler determines the types of load-store units (LSUs) to instantiate and whether to coalesce memory accesses based on from the memory access pattern that the compiler infers.
The Intel® HLS Compiler instantiates the following the types of LSUs:
- Burst-coalesced LSUs
- Nonaligned burst-coalesced LSUs
- The Intel® HLS Compiler typically instantiates burst-coalesced LSUs for accessing variable-latency Avalon® MM Host interfaces.
- Pipelined LSUs
- Never-stall pipelined LSUs
- The Intel® HLS Compiler typically instantiates pipelined LSUs for accessing fixed-latency Avalon® MM Host interfaces or on-chip memories.
Click LSUs in the System Viewer (in the High-Level Design Reports) to see which types of LSU the compiler instantiated for your component.
Figure 4. Example of LSU Information Provided in the System Viewer
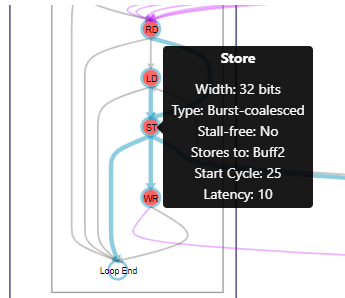
Burst-Coalesced Load-Store Units
By default, the compiler infers burst-coalesced load-store units (LSUs) for any variable-latency Avalon® MM Host interface.
A burst-coalesced LSU dynamically buffers contiguous memory requests until the largest possible burst can be made or until the LSU receives no new requests for a given period of time. The largest possible burst is defined by the ihc::maxburst parameter. For noncontiguous memory requests, a burst-coalesced LSU flushes the buffer between requests.
Burst-coalsced LSUs provide efficient, variable-latency access to memories outside of your component. However, they require a considerable amount of FPGA resources.
The following code example results in the Intel® HLS Compiler instantiating two burst-coalesced LSUs by default (because of the variable-latency Avalon® MM Host interface):
#include "HLS/hls.h"
component void
burst_coalesced(ihc::mm_host<int, ihc::dwidth<64>, ihc::awidth<32>,
ihc::aspace<1>, ihc::latency<0>> &in,
ihc::mm_host<int, ihc::dwidth<64>, ihc::awidth<32>,
ihc::aspace<2>, ihc::latency<0>> &out,
int i) {
int value = in[i / 2]; // Burst-coalesced LSU
out[i] = value; // Burst-coalesced LSU
}
Depending on the memory access pattern and other attributes, the compiler might modify a burst-coalesced LSU to be a nonaligned burst-coalesced LSU.
Nonaligned Burst-coalesced LSUs
When a burst-coalesced LSU can access a memory that is not aligned to the external memory word size, the Intel® HLS Compiler creates a nonaligned burst-coalesced LSU. Nonaligned LSUs typically require more FPGA resources to implement than aligned LSUs. The throughput of a nonaligned LSU might be reduced if it receives many unaligned requests.
The following code example results in two nonaligned burst-coalesced LSUs:
#include "HLS/hls.h"
struct State {
int x;
int y;
int z;
};
component void
static_coalescing(ihc::mm_host<State, ihc::dwidth<128>, ihc::awidth<32>,
ihc::aspace<1>, ihc::latency<0>> &in,
ihc::mm_host<State, ihc::dwidth<128>, ihc::awidth<32>,
ihc::aspace<2>, ihc::latency<0>> &out,
int i) {
out[i] = in[i]; // Two Nonaligned Burst-coalesced LSUs
The figure that follows (Nonaligned Memory Accesses) shows the external memory contents for the previous code example and the nonaligned burst-coalesced LSUs in the component pipeline.
The data type that is read and written is a 96-bit-wide struct. The external memory width is 128 bits. This difference between the read/write data width and the external memory width forces some of the memory requests to span two consecutive memory words.
A nonaligned burst-coalesced LSU can detect that discrepancy and serve such memory requests as needed while still buffering contiguous requests until the largest possible burst can be made.
Figure 5. Nonaligned Memory Accesses
Pipelined Load-Store Units
By default, the compiler infers pipelined load-store units (LSUs) for any fixed-latency Avalon® MM Host interface and on-device memories
In a pipelined LSU, requests are submitted when they are received and no buffering occurs. Pipelined LSUs are also used for accessing memories inside your component.
You can tell the compiler to instantiate pipelined LSUs for variable-latency MM Host interfaces. However, variable-latency interface access with pipelined LSUs might reduce throughput because pipelined LSUs do not combine sequential memory requests into bursts.
Memory accesses are pipelined, so multiple requests can be in flight at the same time.
The following code example results in the Intel® HLS Compiler instantiating four pipelined LSUs:
#include "HLS/hls.h"
component void
pipelined(ihc::mm_host<int, ihc::dwidth<64>, ihc::awidth<32>,
ihc::aspace<1>, ihc::latency<2>> &in,
ihc::mm_host<int, ihc::dwidth<64>, ihc::awidth<32>,
ihc::aspace<1>, ihc::latency<2>> &out,
int gi, int li) {
int lmem[1024];
int res = in[gi]; // Pipelined LSU
for (int i = 0; i < 4; i++) {
lmem[li - i] = res; // Pipelined LSU
res >>= 1;
}
res = 0;
for (int i = 0; i < 4; i++) {
res ^= lmem[li - i]; // Pipelined LSU
}
out[gi] = res; // Pipelined LSU
}
Never-Stall Pipelined LSUs
If a pipelined LSU is connected to a memory inside the component or to a fixed-latency MM Host interface without arbitration, a never-stall LSU is created because all accesses to the memory take a fixed number of cycles that are known to the compiler.
The following code example results in the Intel® HLS Compiler instantiating three never-stall pipelined LSUs for accessing array lmem.
#include "HLS/hls.h"
component void
neverstall(ihc::mm_host<int, ihc::dwidth<128>, ihc::awidth<32>,
ihc::aspace<1>, ihc::latency<0>> &in,
ihc::mm_host<int, ihc::dwidth<128>, ihc::awidth<32>,
ihc::aspace<1>, ihc::latency<0>> &out,
int gi, int li) {
int lmem[1024];
for (int i = 0; i < 1024; i++)
lmem[i] = in[i]; // Pipelined never-stall LSU
out[gi] = lmem[li] ^ lmem[li + 1]; // Pipelined never-stall LSU
}