PyTorch* Optimizations from Intel
Speed Up AI from Research to Production Deployment
Maximize PyTorch Performance on Intel® Hardware
PyTorch* is an AI and machine learning framework popular for both research and production usage. This open source library is often used for deep learning applications whose compute-intensive training and inference test the limits of available hardware resources.
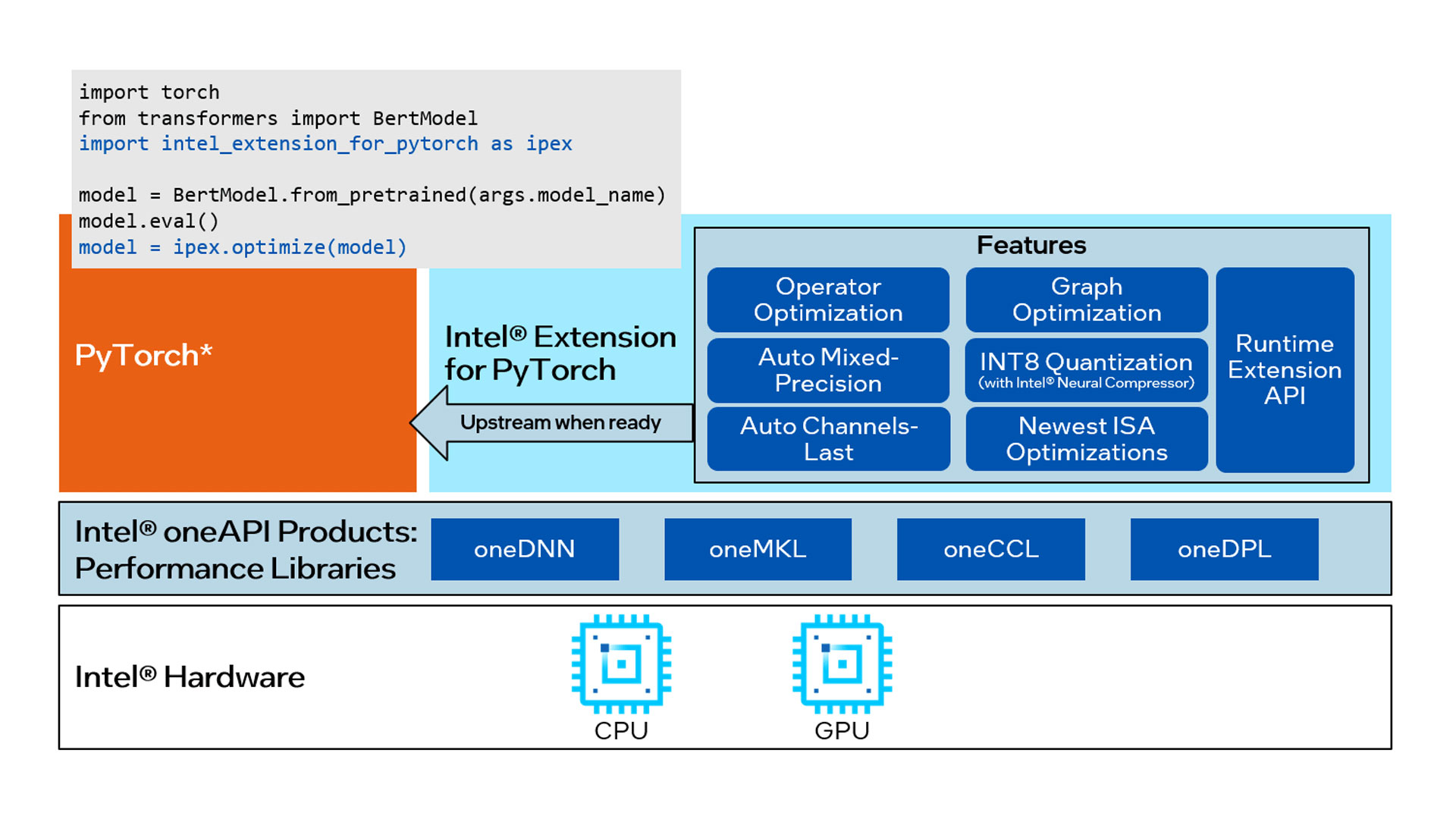
Intel releases its newest optimizations and features in Intel® Extension for PyTorch* before upstreaming them into open source PyTorch.
With a few lines of code, you can use Intel Extension for PyTorch to:
- Take advantage of the most up-to-date Intel software and hardware optimizations for PyTorch.
- Automatically mix different precision data types to reduce the model size and computational workload for inference.
- Add your own performance customizations using APIs.
Intel also works closely with the open source PyTorch project to optimize the PyTorch framework for Intel hardware. These optimizations for PyTorch, along with the extension, are part of the end-to-end suite of Intel® AI and machine learning development tools and resources.
Download the AI Tools
PyTorch and Intel Extension for PyTorch are available in the AI Tools Selector, which provides accelerated machine learning and data analytics pipelines with optimized deep learning frameworks and high-performing Python* libraries.
Develop in the Cloud
Build and optimize oneAPI multiarchitecture applications using the latest Intel-optimized oneAPI and AI tools, and test your workloads across Intel® CPUs and GPUs. No hardware installations, software downloads, or configuration necessary.
Download the Stand-Alone Versions
Stand-alone versions of PyTorch and Intel Extension for PyTorch are available. You can install them using a package manager or build from the source.
Help Intel® Extension for PyTorch* Evolve
This open source component has an active developer community. We welcome you to participate.
Open Source Version (GitHub*)
Features
{kind=link}
Open Source PyTorch Powered by Optimizations from Intel
- Accelerate PyTorch training and inference with Intel® oneAPI Deep Neural Network Library (oneDNN) features such as graph and node optimizations.
- Take advantage of Intel® Deep Learning Boost, Intel® Advanced Vector Extensions (Intel® AVX-512), and Intel® Advanced Matrix Extensions (Intel® AMX) instruction set features to parallelize and accelerate PyTorch workloads.
- Perform distributed training with oneAPI Collective Communications Library (oneCCL) bindings for PyTorch.
Intel Extension for PyTorch Optimizations and Features
- Apply the newest performance optimizations not yet in PyTorch with minimal code changes.
- Parallelize operations without having to analyze task dependencies.
- Automatically mix operator data type precision between float32 and bfloat16 to reduce computational workload and model size.
- Convert to a channels-last memory format for faster image-based deep learning performance.
- Control aspects of the thread runtime such as multistream inference and asynchronous task spawning.
- Run PyTorch on Intel GPU hardware.
Optimized Deployment with OpenVINO™ Toolkit
- Import your PyTorch model into OpenVINO Runtime to compress model size and increase inference speed.
- Instantly target Intel CPUs, GPUs (integrated or discrete), NPUs, or FPGAs.
- Deploy with OpenVINO model server for optimized inference in microservice applications, container-based, or cloud environments. Scale using the same architecture API as KServe for inference execution and inference service provided in gRPC* or REST.
Access the latest AI benchmark performance data for PyTorch and OpenVINO toolkit when running on data center products from Intel. Performance Data.
Documentation & Code Samples
- PyTorch Documentation
- PyTorch Performance Tuning Guide
- Intel Extension for PyTorch
- TorchServe with Intel Extension for PyTorch
- oneCCL Bindings for PyTorch
Intel Extension for PyTorch Code Samples
- Single-Instance Training
- bfloat16 Inference—Imperative Mode
- bfloat16 Inference—TorchScript Mode
- int8 Deployment—Graph Mode
- C++ Dynamic Library
- GPU Single-Instance Training
- GPU Inference
Training & Tutorials
Accelerate PyTorch Training and Inference Performance Using Intel AMX
Llama 2 Inference with PyTorch on Intel® Arc™ A-series GPUs
Build an Interactive Chat-Generation Model Using DialoGPT and PyTorch
Stable Diffusion* with Intel Arc GPUs
Accelerated Image Segmentation Using PyTorch
Visual Quality Inspection for the Pharmaceutical Industry
Get Faster PyTorch Programs with TorchDynamo
How to Improve TorchServe Inference Performance with Intel Extension for PyTorch
Demonstrations
Optimize Text and Image Generation Using PyTorch
Learn how to speed up generative AI that runs on CPUs by setting key environment variables, by using ipex.llm.optimize() for a Llama 2 model and ipex.optimize() for a Stable Diffusion model.
Build an End-to-End Language Identification with PyTorch
Follow along with a code sample that performs language identification from audio samples using the Hugging Face SpeechBrain* toolkit. Learn how to optimize the model for inference on CPU or GPU using Intel Extension for PyTorch.
Predict Forest Fires Using Transfer Learning on a CPU
This application classifies aerial photos according to the fire danger they convey. It uses the MODIS fire dataset to adapt a pretrained ResNet-18 model.
Optimize PyTorch* Performance on the Latest Intel® CPUs and GPUs
Get deep insight into Intel Extension for PyTorch, learning the optimizations that deliver speedups on CPU and GPU. See these optimizations applied to computer vision and NLP models.
Case Studies
Intel and Microsoft Azure* Accelerate PadChest and fMRI Models
Using Intel Extension for PyTorch with the OpenVINO toolkit, this project optimized for deployment to Intel CPUs a chest X-ray image classification dataset and a brain functional magnetic resonance imaging (fMRI) resting-state classification model.
L&T Technology Services Enhances Chest Radiology Outcomes
Chest-rAI* is a deep learning algorithm developed by L&T Technology Services (LTTS) to detect and isolate abnormalities in chest X-ray imagery. LTTS adopted the AI Tools and OpenVINO toolkit, reducing inference time by 46% and reducing their product development time from eight weeks to two weeks.
Hugging Face* Accelerates Stable Diffusion* on CPUs
Automatic mixed precision in Intel Extension for PyTorch helped this application take advantage of Intel AMX to speed up inference latency by 2x.
HippoScreen Improves AI Performance by 2.4x
The Taiwan-based neurotechnology startup used tools and frameworks in the Intel® oneAPI Base Toolkit and AI Tools to the improve the efficiency and training times of deep learning models used in its Brain Waves AI system.
News
PyTorch v2.1 Contains New Performance Features for AI Developers
Intel made significant contributions to five new features that include TorchInductor-CPU optimizations, a CPU dynamic shape inference path for torch.compile, and a C++ wrapper.
Intel Joins the PyTorch Foundation
Intel is now a Premier member of the PyTorch Foundation, with four full-time PyTorch maintainers for CPU performance, and a seat on the PyTorch Foundation Governing Board.
Introducing Intel Extension for PyTorch for GPUs
This extension now supports Intel GPUs. Learn which features are supported in this release, how to install it, and how to get started running PyTorch on Intel GPUs.
Specifications
Processors:
- Intel Xeon processor
- Intel® Core™ processor
- Intel GPU
Operating systems:
- Linux* (Intel Extension for PyTorch is for Linux only)
- Windows*
Languages:
- Python
- C++
Deploy PyTorch models to a variety of devices and operating systems with Intel Distribution of OpenVINO Toolkit.
Get Help
Your success is our success. Access these support resources when you need assistance.
Stay Up to Date on AI Workload Optimizations
Sign up to receive hand-curated technical articles, tutorials, developer tools, training opportunities, and more to help you accelerate and optimize your end-to-end AI and data science workflows. Take a chance and subscribe. You can change your mind at any time.