自顶向下的微架构分析方法
使用此方法可以了解应用程序如何利用可用的硬件资源,以及如何 CPU 微架构相关的性能数据。获取这种知识的一种方法是使用片上性能监控单元 (PMUs) 。
内容专家: Dmitry Ryabtsev
PMUs 是 CPU 内核中的专用逻辑块,用于记录计算系统上发生的特定硬件事件。 这些事件可能是缓存遗漏或分支错误预测。 我们可以观察到这些事件,并将它们组合起来创建有用的高级指标,如 CPI 。
一个特定的微架构可以通过其 PMU 提供数百个事件。 然而,确定哪些事件在检测和修正特定性能问题时,有时不是显而易见的。 我们往往需要深入了解微架构设计和 PMU ,才能从原始事件数据中获得有用的信息。 但是您可以使用预定义的事件和指标,以及自上而下的特性描述方法将数据转换为可操作的信息。
通过研究 PMU 分析过程来学习该方法以及如何在英特尔 ®VTune™ 分析器上使用该方法。
自顶向下的微架构分析方法概述
现代CPU采用流水线(pipelining)以及硬件线程、乱序执行和指令级并行等技术来尽可能有效地利用资源。 尽管如此,一些类型的软件模式和算法仍然会导致效率低下。 例如,链接数据结构通常在软件中使用,但这却会导致间接寻址,并且使得硬件预取器(hardware prefetchers)失效。 在许多情况中,当数据被检索并且没有其它指令可执行时,这种行为会在流水线流水线中创建等待状态 (bubbles of idleness)。 在解决软件问题时,链接数据结构是一种非常合适的解决方法,然而这可能会导致效率低下。还有许多其它软件方面的例子,可以佐证它们对底层CPU流水线的影响。 基于自顶向下微架构分析方法,旨在让您了解您是否对算法和数据结构做出了明智的选择。 通过 Intel® 64 and IA-32 Architectures Optimization Reference Manual, Appendix B.1 获取有关自顶向下微架构分析方法的更多细节。
自顶向下的特性描述是一个基于事件的度量,它可以识别应用程序中的主要性能瓶颈。 它的目的是显示CPU的流水线在运行应用程序时的平均利用率。 以前,解释事件的框架依赖于计算CPU时钟周期(clock tick)——即确定多少CPU时钟周期被用于那种类型的操作(例如,由于L2缓存未命中)。 与之前不同,这一框架则是基于计算流水线的资源而来的。 要理解自顶向下的特性描述,我们需要从高层次上探索一些底层的微架构概念。 微体架构的许多细节在这个框架中被抽象出来,这使得您不必是硬件专家也可以使用和理解它。
现代高性能CPU的流水线相当复杂。 在下方的简化视图中,流水线在概念上分为两部分,前端和后端。 前端负责获取以体系结构指令表示的程序代码,并将其解码为一个或多个低级硬件操作 ,这被称为micro-ops(uOps).然后在一个名为分配(allocation)的过程中,uOps被输送到后端。在分配之后,后端负责监控uOp的操作数(data operand)何时可用,并在可用的执行单元中执行uOp。 当uOp的执行完成后,我们把它称作执行完成(retirement),并且 uOp的结果会被提交到体系结构状态(CPU寄存器或写回内存)。 通常情况下,大多数uOps会完全通过流水线并退出,但有时投机获取的uOps可能会在退出前被取消——比如错误预测的分支。
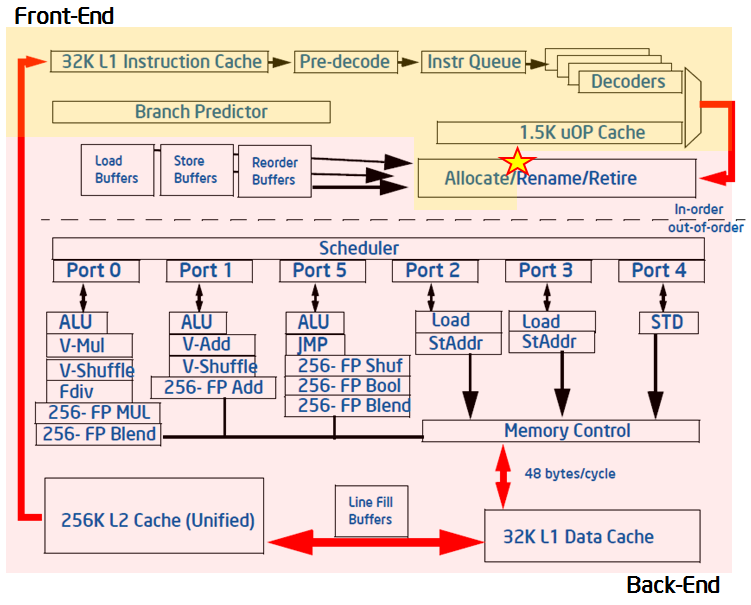
在最近的Intel微架构中,流水线的前端每个周期可以分配4个uOps,而后端每个周期可以执行完成4个uOps。 从这些功能中可以得出流水线槽(pipeline slot)的抽象概念。 流水线槽表示处理一个uOp所需的硬件资源。 自顶向下的特性描述假设对于每个CPU内核,在每个时钟周期上,有四个流水线槽可用。 然后,它使用专门设计的PMU事件来衡量这些流水线槽的利用率。 流水线槽的状态在分配点(在上图中用星号标记)处获取,这里uOps离开前端并到达后端。 在应用程序运行时可用的每个流水线槽将根据上面描述的简化流水线视图分为四类。
在任何周期中,流水线槽可以是空的,也可以用uOp填充。 如果一个槽位在一个时钟周期内是空的,这将被归于停滞(stall)。 下一步需要对流水线槽进行分类,确定是流水线的前端部分还是后端部分造成了停滞。 这可以通过使用指定的PMU事件和公式来完成。 自顶向下特性描述的目标是确定主要的瓶颈,因此,将停滞归因于前端或后端将会是一个关键的考虑点。 通常,如果停滞是由于前端无法用uOp填充槽造成的,那么在此周期它将被归类为前端绑定槽,这意味着性能受到前端绑定类别下的某些瓶颈的限制。 如果前端已准备好uOp,但由于后端尚未准备好处理它而因此无法交付它,则空流水线槽将被分类为后端绑定类别。 后端停滞(backend stalls)通常是由后端耗尽某些资源(例如,负载缓冲区)造成的。 但是,如果前端和后端都停止了,那么插槽将被归类为后端。 这是因为,在这种情况下,修复前端的停滞很可能对应用程序的性能没有帮助。 后端的瓶颈是限制性的,它需要在修复前端的问题前先被移除。
如果处理器没有停止,那么流水线插槽将在分配点被uOp填满。 在本例中,如何对槽进行分类的决定因素是uOp最终是否执行完成。 如果它执行完成了,这个槽被归类为完成。 如果没有,无论是由于前端的不正确的分支预测,还是由于自修改代码导致的流水线刷新之类的清除事件,该槽将被归类为Bad Speculation。 这四个类别构成了自顶向下描述的最高级。为了描述一个应用程序,每个流水线槽被精确地分为以下四类之一:
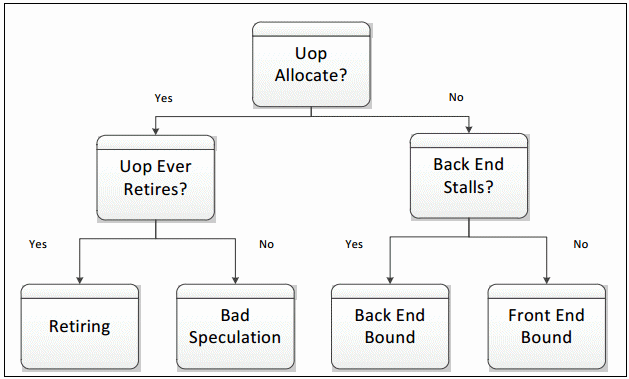
这四类流水线槽的分布是非常有用的。 尽管基于事件的度量已经实现很多年了,但是在此描述之前还没有方法来确定哪些可能的性能问题最具影响。 当将性能指标放入这个框架时,您可以看到哪些问题需要首先解决。 将流水线槽分类为四类所需的事件可以从英特尔®微架构代号Sandy Bridge开始(Sandy Bridge被用于第二代英特尔Core处理器家族和英特尔Xeon®处理器E5家族)。 随后的微体系结构可能允许将这些高级类别进一步分解为更详细的性能指标。
使用VTune分析器的自顶向下分析方法
英特尔®VTune™ 分析器提供了Microarchitecture Exploration analysis type,它预先配置来收集自顶向下特性描述中定义的事件。这一事件是从英特尔微架构代号Ivy Bridge开始。 微架构探索还收集计算许多其它计算有用性能指标所需的事件。 微架构探索分析的结果默认显示在微架构探索视角中(Microarchitecture Exploration viewpoint )。
微架构探索结果显示在层次列中,以加强特性描述自顶向下的结果。总结窗口给出了整个应用程序中每个类别中流水线槽的百分比。 您可以通过多种方式查看结果。 查看结果的最常见方法是在功能级别查看指标 :
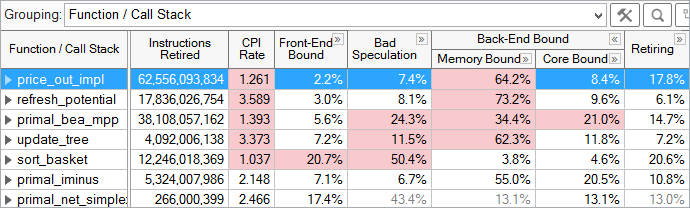
对于每个选项,显示了每个类别中流水线槽的比例。 例如 , 对于 上图所选的 price_out_impl 选项,有 2.2% 的流水线槽在前端类别, 7.4% 在 Bad Speculation , 64.2% 在内存瓶颈, 8.4% 在内核瓶颈, 17.8% 在执行完成类别。 每个类别都可以展开来查看该类别下的指标。 自动高亮显示用于将您的注意力吸引到潜在问题区域,在本例中,这是内存瓶颈流水线槽的高百分比。
微架构优化方法
在进行任何性能调优时,关注应用程序的最顶层的热点是很重要的。热点是占用最多CPU时间的功能。关注这些点将确保优化会影响整个应用程序性能。 VTune分析器有一个热点分析功能,它有两种特定的收集模式: 用户模式采样和基于硬件事件的抽样。在微架构探索观点中,热点可以通过确定具有最高时钟周期事件计数的功能或模块来识别,这些事件计数会测量CPU时钟周期的数量。 欲从微架构调优中获得最大的收益,请确保已经应用了算法优化,比如添加并行性。 通常我们会先执行系统优化,然后是应用程序级算法优化,再然后是体系结构和微架构优化。 此过程也被称为“自顶向下”,正如自顶向下软件调优方法中所说。 它以及其他重要的性能调优方面(如工作负载选择)在De-Mystifying Software Performance Optimization一文中进行了描述。
- 选择一个热点功能(在应用程序总时钟周期中占很大比例的一个)。
- 使用自顶向下方法和下面给出的指导方针评估该热点的效率。
- 如果效率不高,可以向下选取代表主要瓶颈的类别,并使用下一级的子瓶颈来确定原因。
- 优化问题(s)。VTune分析器调优指南包含针对每个类别中的许多底层性能问题的特定调优建议。
- 重复,直到所有重要的热点地区都被评估。
如果度量值超出预定义的阈值并出现在热点中,那么VTune 分析器会自动高亮GUI中的度量值。如果一个功能内累积的时钟周期总数超过该功能的5%,那么VTune分析器会将该功能归类为热点。 确定特定类别中的流水线槽是否构成瓶颈可能会由工作量(workload)来决定,但下表提供了一些一般指导原则:
Expected Range of Pipeline Slots in This Category, for a Hotspot in a Well-Tuned: |
|||
|---|---|---|---|
Category |
Client/Desktop Application |
Server/Database/Distributed application |
High Performance Computing (HPC) application |
Retiring |
20-50% |
10-30% |
30-70% |
Back-End Bound |
20-40% |
20-60% |
20-40% |
Front-End Bound |
5-10% |
10-25% |
5-10% |
Bad Speculation |
5-10% |
5-10% |
1-5% |
这些阈值基于对英特尔实验室中的一些工作负载的分析。 如果一个热点在某个类别中(执行完成除外)花费的时间比例较高或高于所指示的范围,那么调查它可能是有用的。 如果这对一个以上的类别需要查看时,那么应该首先调查时间比例最高的类别。 请注意,预计热点将在每个类别中花费一些时间,低于正常范围的值可能并不表示有问题。
关于自上至下的方法,需要认识到的重要一点是,您不需要花时间优化没有被确定为瓶颈的类别中的问题——这样做可能不会导致显著的性能改进。
优化后端绑定类别
大多数未调优的应用程序都是后端瓶颈的。 解决后端问题通常与解决延迟源有关,延迟源会导致执行完成所需的时间超过必要时间。 在英特尔的微架构代号Sandy Bridge上,VTune分析器具有后端瓶颈指标来查找高延迟的来源。 例如,LLC Miss (Last-Level Cache Miss)度量确定了需要访问DRAM以获取数据的代码区域,而Split Loads和Split Stores度量指出了可能损害性能的内存访问模式。 有关英特尔微体系结构代号Sandy Bridge度量的详细信息,请参见调优指南。从英特尔微架构代号Ivy Bridge(在第三代Intel Core处理器家族中使用)开始,可以通过事件将后端瓶颈分类分为内存瓶颈和内核瓶颈子指标。 前4个类别之下的指标可以使用流水线槽域(domain)以外的域。 每个指标将基于底层PMU事件使用最适当的域。 有关更多细节,请参见每个指标或类别的文档。
内存和内核瓶颈子指标是通过使用与执行单元的使用相对应的事件确定的——与顶层分类中使用的分配阶段相反。 因此,这些指标的总和不一定与顶层确定的后端瓶颈比率相匹配(尽管它们相互关联得很好)。
内存瓶颈类别中的停滞有与内存子系统相关的原因。 例如,缓存未命中和内存访问可能导致内存瓶颈的停滞。 内核瓶颈停滞是由于在每个周期中对CPU中可用执行单元的使用没有达到最佳状态造成的。 例如,一行中的多个多周期指令,争夺执行单元可能导致执行单元低效执行。 对于这种故障,槽只有在它们被停止并且没有未完成的内存访问时才被归类为内核瓶颈。 例如,如果有挂起的负载,则将周期归类为内存瓶颈,因为在负载尚未返回数据时,执行单元正在等待。 PMU事件被设计到硬件中,专门记录这种类型的问题,这有助于识别应用程序中的真正瓶颈。 大多数后端瓶颈问题都属于内存瓶颈类别。
内存瓶颈类别下的大多数指标确定了从L1缓存到内存的内存层次结构的那个级别是瓶颈。 同样,用于进行这一确定的事件也是经过精心设计的。 一旦后端停止,指标将尝试将负载的停止归因于特定级别的缓存或正在运行的存储。 如果热点瓶颈在给定的级别,这意味着它的大部分数据都是从该缓存或内存级别检索的。 优化应该集中于将数据移到更靠近内核的地方。 存储绑定也作为一个子类别调用,它可以指示依赖项——例如当流水线中的加载将会依赖于以前的存储时。 在每个类别下,都有一些指标可以识别导致内存瓶颈执行的特定应用程序行为。 例如,被Store Forwarding阻止的负载和4k Aliasing是标记可能导致应用程序被L1绑定的行为的指标。
核心 瓶颈 停滞在后端 瓶颈 中通常不太常见。 这种情况会出现在可用的计算资源没有得到充分利用和 / 或在没有显著内存需求的情况下使用时。 例如,一个对缓存的数据进行浮点 (FP) 运算的循环。 VTune 分析器提供一些指标来检测此类别中的行为。 例如,当除法硬件被大量使用时,除法指标会标识周期,而端口利用率指标会标识执行单元之间的竞争。
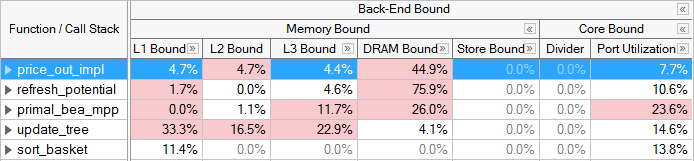
注解:
NOTE:
灰色的度量值表明为这个度量收集的数据是不可靠的。 例如,如果为PMU事件收集的示例数量太少,就可能发生这种情况。 您可以忽略此数据,也可以在增加数据收集时间、采样间隔或工作量后重新运行收集。
优化前端绑定类别
前端绑定类别涵盖了其他几种类型的流水线停滞。 流水线的前端部分成为应用程序的瓶颈并不常见; 然而,在某些情况下,前端可以在很大程度上造成机器停滞。 例如,JITed代码和可理解的代码可能导致前端停滞,因为指令流是动态创建的,而且没有编译器代码事先布局的益处。 提高前端绑定类的性能通常与代码布局(热代码(hot code)的位置)和编译器技术有关。 例如,分支代码或占用空间大的代码可能会突出显示前端绑定类别。 像代码大小优化和编译器配置文件引导优化(PGO)这样的技术在很多情况下都可能减少停滞。
基于Intel微架构(代号Ivy Bridge及以上)的自顶向下方法将前端绑定中断分为两类:前端延迟和前端带宽。 前端延迟度量会报告在一个周期的范围内前端没有处理uOps,而后端已经准备好使用它们的周期。 回想一下,前端集群每个周期最多可以处理4个uOps。 前端带宽度量将会报告处理数量小于4个uOps的周期,这意味着对前端能力的低效率使用。 在每个类别下面我们又确定了进一步的指标。
根据在从Intel微架构(代号Ivy Bridge)开始,前端延迟下的分支Resteers瓶颈指标所记载的分支错误预测,主要是出现在Bad Speculation类别中,可能导致前端的低效率
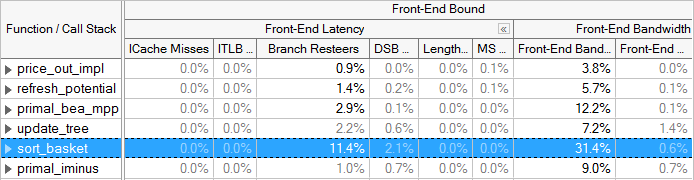
Vtune会列出可能确定导致前端绑定代码原因的指标。 如果这些类别中的任何一个大量出现在结果中,那么深入挖掘这一度量以确定它们的原因和如何纠正它们。 例如,ITLB开销(overhead)(指令转换后备缓冲区开销)和ICache Miss(指令缓存缺失)指标可能指出有前端绑定执行的问题的区域。 有关的优化建议,请参见VTune分析器调优指南。
Bad Speculation类别调优
第三个顶层类别,即Bad Speculation,表明了流水线何时正忙于获取和执行无用的操作。 Bad Speculation流水线插槽是当机器从错误的投机中恢复时,处理从不完成和停滞的uOps的流水线,也因而是被浪费的流水线。Bad Speculation是由分支错误预测和机器清除引起的,而不太常见的情况下会由自修改代码这样的情况引起。 Bad Speculation可以通过编译器技术来减少,如配置文件引导优化(PGO),避免间接分支,并消除导致机器清除的错误条件。 纠正Bad Speculation的问题也可以帮助减少前端绑定中断的数量。 对于特定的调优技术,请参阅适合您的微架构的VTune分析器调优指南。
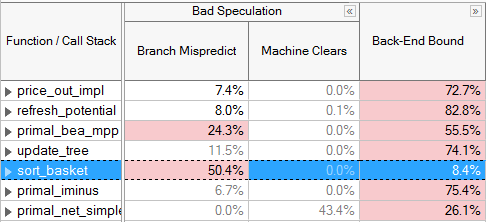
执行完成类别的调优
最后一个顶层类别是执行完成类别。 它表示流水线什么时候忙着执行那些通常有用的操作。 理想情况下,应用程序应该有尽可能多的这类插槽。 然而,即使是那些拥有大量执行完成流水线插槽的代码区域也可能有改进的空间。大量使用微序列器是一个归入执行完成类别的性能问题,它通过生成一长串uOps。 在这种情况下,尽管有许多执行完成的uOps,但其中一些是可以避免的。 例如,在异常情况下,应用的浮点执行异常通常可以通过编译器选项(如DAZ或FTZ)来减少。 代码生成选择也可以帮助缓解这些问题,更多细节请参见VTune分析器调优指南。 在Intel微架构(代号Sandy Bridge)中,我们使用助攻来作为执行完成类别的度量。 在Intel微架构(代号Ivy Bridge及以上)中,理想的执行完成类别的流水线槽会被分解成一个称为一般执行完成(General Retirement)的子类别,而微码序列器(Microcode Sequencer)uOps则被单独标识。
如果还没有这样做,那么像并行化和向量化这样的算法调优技术可以帮助改善属于执行完成类别的代码区域的性能。
结论
自顶向下方法及其在VTune分析器中的可用性表示了一种使用PMUs进行性能调优的新方向。 开发人员花时间来熟悉这种特性是值得的,因为对它的支持被设计到最近的PMUs中,并且在可能的情况下,该层次结构将在未来的Intel微架构中进一步扩展。 例如,在Intel微架构(代号Sandy Bridge)和Intel微架构(代号Ivy Bridge)之间,这一特性描述进行了显著扩展。
自顶向下方法的目标是识别应用程序性能的主要瓶颈。 微架构分析和VTune分析器中的可视化特性的目的是为您提供改进应用程序的可操作信息。 这些功能结合在一起,不仅可以显著提高应用程序的性能,还可以显著提高优化的结果。
Parent topic: 分析方法论