Visible to Intel only — GUID: GUID-9EBDBDAD-51AA-4A6E-ADAB-76191B68AE21
Introduction
Install and Launch Intel® Advisor
Set Up Project
Analyze Vectorization Perspective
Analyze CPU Roofline
Model Threading Designs
Model Offloading to a GPU
Analyze GPU Roofline
Design and Analyze Flow Graphs
Minimize Analysis Overhead
Analyze MPI Applications
Manage Results
Command Line Interface
Troubleshooting
Reference
Appendix
Notices and Disclaimers
Annotation Report, Clear Description of Storage Row
Annotation Report, Disable Observations in Region Row
Annotation Report, Pause Collection Row
Annotation Report, Inductive Expression Row
Annotation Report, Lock Row
Annotation Report, Observe Uses Row
Annotation Report, Reduction Row
Annotation Report, Re-enable Observations at End of Region Row
Annotation Report, Resume Collection Row
Annotation Report, Site Row
Annotation Report, Task Row
Annotation Report, User Memory Allocator Use Row
Annotation Report, User Memory Deallocator Use Row
Intel® oneAPI Threading Building Blocks (oneTBB) Mutexes
Intel® oneAPI Threading Building Blocks (oneTBB) Simple Mutex - Example
Test the Intel® oneAPI Threading Building Blocks (oneTBB) Synchronization Code
Parallelize Functions - Intel® oneAPI Threading Building Blocks (oneTBB) Tasks
Parallelize Data - Intel® oneAPI Threading Building Blocks (oneTBB) Counted Loops
Parallelize Data - Intel® oneAPI Threading Building Blocks (oneTBB) Loops with Complex Iteration Control
Add OpenMP Code to Synchronize the Shared Resources
OpenMP Critical Sections
Basic OpenMP Atomic Operations
Advanced OpenMP Atomic Operations
OpenMP Reduction Operations
OpenMP Locks
Test the OpenMP Synchronization Code
Parallelize Functions - OpenMP Tasks
Parallelize Data - OpenMP Counted Loops
Parallelize Data - OpenMP Loops with Complex Iteration Control
Offload Modeling Report Overview
Examine Regions Recommended for Offloading
Accuracy Level
Enabled Analyses
Result Interpretation
Next Steps
See Also
Examine Data Transfers for Modeled Regions
Check for Dependency Issues
Explore Performance Gain from GPU-to-GPU Modeling
Investigate Non-Offloaded Code Regions
Where to Find the Flow Graph Analyzer
Launching the Flow Graph Analyzer
Flow Graph Analyzer GUI Overview
Flow Graph Analyzer Workflows
Designer Workflow
Generating C++ Stubs
Preferences
Scalability Analysis
Collecting Traces from Applications
Nested Parallelism in Flow Graph Analyzer
Analyzer Workflow
Experimental Support for OpenMP* Applications
Sample Trace Files
Additional Resources
accuracy
append
app-working-dir
assume-dependencies
assume-hide-taxes
assume-ndim-dependency
assume-single-data-transfer
auto-finalize
batching
benchmarks-sync
bottom-up
cache-binaries
cache-binaries-mode
cache-config
cache-simulation
cache-sources
cachesim
cachesim-associativity
cachesim-cacheline-size
cachesim-mode
cachesim-sampling-factor
cachesim-sets
check-profitability
clear
config
count-logical-instructions
count-memory-instructions
count-memory-objects-accesses
count-mov-instructions
count-send-latency
cpu-scale-factor
csv-delimiter
custom-config
data-limit
data-reuse-analysis
data-transfer
data-transfer-histogram
data-transfer-page-size
data-type
delete-tripcounts
disable-fp64-math-optimization
display-callstack
dry-run
duration
dynamic
enable-cache-simulation
enable-data-transfer-analysis
enable-task-chunking
enforce-baseline-decomposition
enforce-fallback
enforce-offloads
estimate-max-speedup
evaluate-min-speedup
exclude-files
executable-of-interest
exp-dir
filter
filter-by-scope
filter-reductions
flop
force-32bit-arithmetics
force-64bit-arithmetics
format
gpu
gpu-carm
gpu-sampling-interval
hide-data-transfer-tax
ignore
ignore-app-mismatch
ignore-checksums
instance-of-interest
integrated
interval
limit
loop-call-count-limit
loop-filter-threshold
loops
mark-up
mark-up-list
memory-level
memory-operation-type
mix
mkl-user-mode
model-baseline-gpu
model-children
model-extended-math
model-system-calls
module-filter
module-filter-mode
mpi-rank
mrte-mode
ndim-depth-limit
option-file
overlap-taxes
pack
profile-gpu
profile-intel-perf-libs
profile-jit
profile-python
profile-stripped-binaries
project-dir
quiet
recalculate-time
record-mem-allocations
record-stack-frame
reduce-lock-contention
reduce-lock-overhead
reduce-site-overhead
reduce-task-overhead
refinalize-survey
remove
report-output
report-template
result-dir
resume-after
return-app-exitcode
search-dir
search-n-dim
select
set-dependency
set-parallel
set-parameter
show-all-columns
show-all-rows
show-functions
show-loops
show-not-executed
show-report
small-node-filter
sort-asc
sort-desc
spill-analysis
stack-access-granularity
stack-stitching
stack-unwind-limit
stacks
stackwalk-mode
start-paused
static-instruction-mix
strategy
support-multi-isa-binaries
target-device
target-gpu
target-pid
target-process
target-system
threading-model
threads
top-down
trace-mode
trace-mpi
track-memory-objects
track-stack-accesses
track-stack-variables
trip-counts
verbose
with-stack
Error Message: Application Sets Its Own Handler for Signal
Error Message: Cannot Collect GPU Hardware Metrics for the Selected GPU Adapter
Error Message: Memory Model Cache Hierarchy Incompatible
Error Message: No Annotations Found
Error Message: No Data Is Collected
Error Message: Stack Size Is Too Small
Error Message: Undefined Linker References to dlopen or dlsym
Problem: Broken Call Tree
Problem: Code Region is not Marked Up
Problem: Debug Information Not Available
Problem: No Data
Problem: Source Not Available
Problem: Stack in the Top-Down Tree Window Is Incorrect
Problem: Survey Tool does not Display Survey Report
Problem: Unexpected C/C++ Compilation Errors After Adding Annotations
Problem: Unexpected Unmatched Annotations in the Dependencies Report
Warning: Analysis of Debug Build
Warning: Analysis of Release Build
Dangling Lock
Data Communication
Data Communication, Child Task
Inconsistent Lock Use
Lock Hierarchy Violation
Memory Reuse
Memory Reuse, Child Task
Memory Watch
Missing End Site
Missing End Task
Missing Start Site
Missing Start Task
No Tasks in Parallel Site
One Task Instance in Parallel Site
Orphaned Task
Parallel Site Information
Thread Information
Unhandled Application Exception
Dialog Box: Corresponding Command Line
Dialog Box: Create a Project
Dialog Box: Create a Result Snapshot
Dialog Box: Options - Assembly
Editor Tab
Dialog Box: Options - General
Dialog Box: Options - Result Location
Dialog Box: Project Properties - Analysis Target
Dialog Box: Project Properties - Binary/Symbol Search
Dialog Box: Project Properties - Source Search
Pane: Advanced View
Pane: Analysis Workflow
Pane: Roofline Chart
Pane: GPU Roofline Chart
Project Navigator Pane
Toolbar: Intel Advisor
Annotation Report
Window: Dependencies Source
Window: GPU Roofline Regions
Window: GPU Roofline Insights Summary
Window: Memory Access Patterns Source
Window: Offload Modeling Summary
Window: Offload Modeling Report - Accelerated Regions
Window: Perspective Selector
Window: Refinement Reports
Window: Suitability Report
Window: Suitability Source
Window: Survey Report
Window: Survey Source
Window: Threading Summary
Window: Vectorization Summary
Visible to Intel only — GUID: GUID-9EBDBDAD-51AA-4A6E-ADAB-76191B68AE21
Examine Regions Recommended for Offloading
Accuracy Level
Low
Enabled Analyses
Survey + Characterization (Trip Counts and FLOP) + Performance Modeling with no assumed dependencies
Result Interpretation
After running the Offload Modeling perspective with Low accuracy, you get a basic Offload Modeling report, which shows you estimated performance of your application after offloading to a target platform assuming it is mostly bounded by compute limitations.
Offload Modeling with Low accuracy assumes that:
- There is no tax for transferring data between baseline and target platforms.
- All data goes to L1/L3 cache level only. L1/L3 cache traffic estimation might be inaccurate.
- A loop is parallel if the loop dependency type in unknown (Assume Dependencies checkbox is disabled). This happens when there is no information about a loop dependency type from a compiler or the loop is not explicitly marked as parallel, for example, with a programming model (OpenMP*, SYCL, Intel® oneAPI Threading Building Blocks (oneTBB))
NOTE:
This topic describes data as it is shown in the Offload Modeling report in the Intel Advisor GUI and an interactive HTML report.
In the Offload Modeling report:
Review the metrics for the whole application in the Summary tab.
- Check if your application is profitable to offload to a target device or if it has a better performance on a baseline platform in the Program Metrics panes.
- See what prevents your code from achieving a better performance if executed on a target device in the Offload Bounded by pane.
NOTE:If you enable Assume Dependencies option for the Performance Modeling analysis, you might see high percentage of dependency-bound code regions. You are recommended run the Dependencies analysis and rerun Performance Modeling to get more accurate results.
- If the estimated speed-up is high enough and other metrics in the Summary pane suggest that your application can benefit from offloading to a selected target platform, you can start offloading your code.
If you want to investigate the results reported for each region in more detail, go to the Accelerated Regions tab and select a code region:
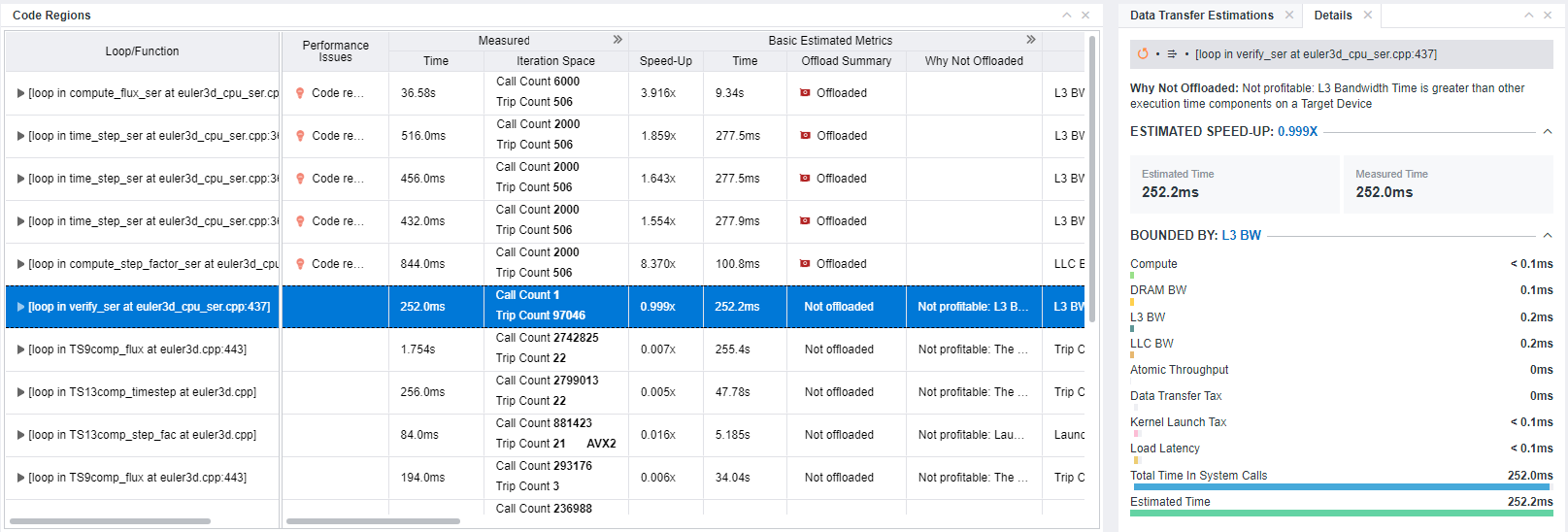
- Check whether your target code region is recommended for offloading to a selected platform. In the Basic Estimated Metrics column group, review the Offload Summary column. The code region is considered profitable for offloading if estimated speed-up is more than 1, that is, estimated time execution on a target device is smaller that on a host platform.
If your code region of interest is not recommended for offloading, consider re-running the perspective with a higher accuracy or refer to Investigate Not Offloaded Code Regions for recommendations on how to model offloading for this code region.
- Examine the Bounded By column of the Estimated Bounded By group in the code region pane to identify the main bottleneck that limits the performance of the code region (see the Bounded by section). The metrics show one or more bottleneck(s) in a code region.
- In the Throughput column of the Estimated Bounded By group, review time spent for compute- and L3 cache bandwidth-bound parts of your code. If the value is high, consider optimizing compute and/or L3 cache usage in your application.
- Review the metrics in the Compute Estimates column group to see the details about instructions and number of threads used in each code region.
- Check whether your target code region is recommended for offloading to a selected platform. In the Basic Estimated Metrics column group, review the Offload Summary column. The code region is considered profitable for offloading if estimated speed-up is more than 1, that is, estimated time execution on a target device is smaller that on a host platform.
- Get guidance for offloading your code to a target device and optimizing it so that your code benefits the most in the Recommendations tab. If the code region has room for optimization or underutilizes the capacity of the target device, Intel Advisor provides you with hints and code snippets that may be helpful to you for further code improvement.
- View the offload summary and details for the selected code region in the Details pane.
For details about metrics reported, see Accelerator Metrics.
Next Steps
- If you think that the estimated speedup is enough and the application is ready to be offloded, rewrite your code to offload profitable code regions to a target platform and measure performance of GPU kernels with GPU Roofline Insights perspective.
- Consider running the Offload Modeling perspective with a higher accuracy level to get a more detailed report.
Parent topic: Explore Offload Modeling Results