Address Compute Capacity Bottlenecks
This topic is part of a tutorial that shows how to use the automated Roofline chart to make prioritized optimization decisions.
Perform the following steps:
Key take-aways from these steps:
Arithmetic Intensity (the x-axis of the Roofline chart) = Floating-point operations per byte accessed. Any given algorithm has an arithmetic Intensity. In theory, optimization should not change this metric because it is a trait of the algorithm itself. So dots on a Roofline chart move up and down as performance changes, but rarely side to side.
Optimizing a loop is not enough to make the corresponding dot rise to the next roofline; a loop must make good use of the optimization. Inefficient vectorization is not good enough; an isolated fused multiply-add instruction (FMA) is not good enough.
In the right circumstances, you can use data layout and memory access optimizations to overcome both compute capacity and memory bandwidth limitations.
Take advantage of code-specific how-can-I-fix-this-issue? advice in the Recommendations tab.
NOTE:
These steps use a prepackaged analysis result because of tutorial duration and hardware dependency considerations.
Open a Result Snapshot
Do one of the following:
If you prefer to work in the standalone GUI, from the File menu, choose Open > Result and choose the Result2.advixeexpz result.
If you prefer to work in the Visual Studio* IDE, from the File menu, choose Open > File and choose the Result2.advixeexpz result.
Focus the Roofline Chart on the Data of Most Interest
Use the display toggles to show the Roofline chart and Survey Report side by side.
On the Intel Advisor toolbar, click the Loops And Functions filter drop-down and choose Loops.
In the Roofline chart:
Select the Use Single-Threaded Loops checkbox.
Click the
 control, then deselect the Visibility checkbox for all SP... roofs. (All variables in this sample code are double-precision, so there is no need to clutter the chart with single-precision rooflines.)
control, then deselect the Visibility checkbox for all SP... roofs. (All variables in this sample code are double-precision, so there is no need to clutter the chart with single-precision rooflines.) 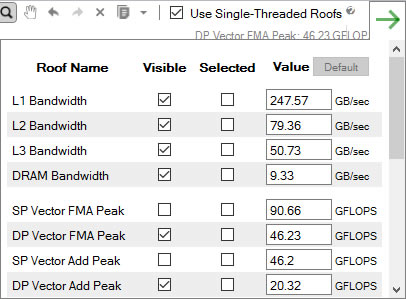
In the Point Colorization section, choose Vectiorized/Scalar to differentiate dot colors by scalar (blue) vs. vectorized (orange) instead of runtime (red, yellow, and green).
Click
 to save your changes.
to save your changes. Click the
 control. In the x-axis fields, backspace over the existing values and enter 0.1 and 0.8. In the y-axis fields, backspace over the existing values and enter 3.1 and 45.5. Click the
control. In the x-axis fields, backspace over the existing values and enter 0.1 and 0.8. In the y-axis fields, backspace over the existing values and enter 3.1 and 45.5. Click the  button to save your changes.
button to save your changes.
Interpret Roofline Chart Data
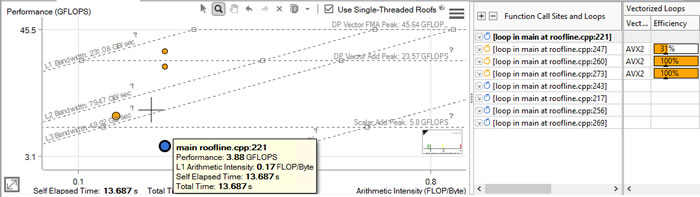
In the Roofline chart, notice the position of the blue dot representing the loop in main at roofline.cpp:221: It is positioned below both the Vector Add Peak and Scalar Add Peak rooflines. Why?
The probable reason: It is not vectorized, as indicated by the dot color. We can also quickly verify this scalar status in the first column of the Survey Report: Blue icon = scalar; orange icon = vectorized. (For the purposes of this tutorial, we used a directive to artificially block this loop from vectorizing. Intel Advisor has a wide variety of tools for diagnosing why loops do not vectorize, which you could use if this loop had a real problem.)
The loop in main at roofline.cpp:247 is a vectorized version of the loop in main at roofline.cpp:221.
In the Roofline chart, notice the position of the bottom orange dot representing this loop moved left on the Arithmetic Intensity axis. Theoretically, this is not possible. Arithmetic intensity = Floating-point operations per byte transferred. Any given algorithm has a specific arithmetic intensity that optimization should not change, because this metric is a trait of the algorithm itself. So dots on a Roofline chart move up as performance improves, but not side to side. Usually.
Apparently, compiler optimizations altered the arithmetic intensity of the loop in main at roofline.cpp:247.
How?
In the Code Analytics tab, check the GFLOPS drop-down region for both loops represented by the blue and bottom orange dots.
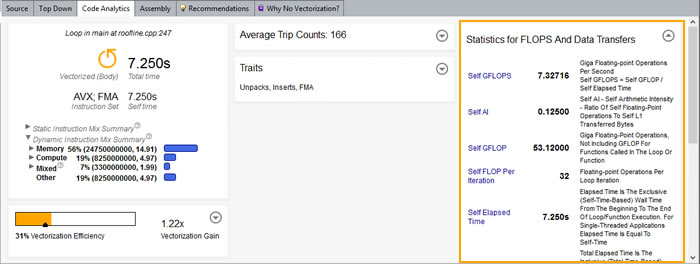
When we examine these statistics for both loops side by side, we can see the Self FLOP Per Iteration is different for the vectorized loop, but this makes sense: The loop has a vector length of 4, and 8*4=32. What changed is the Data Transfers values, both total and per iteration. The 256 cannot be explained by vectorization, because 48*4=192, not 256.
Metrics |
Scalar Loop (Blue Dot) |
Vectorized Loop (Bottom Orange Dot) |
|---|---|---|
Self FLOP Per Iteration |
8 |
32 |
Data Transfers: Total Gigabytes: |
318.720 |
424.960 |
Data Transfers: Bytes Per Loop Iteration |
48 |
256 |
These statistics tell us the compiler altered the memory accesses. New unpack and insert instructions - which are also noted in the Code Analytics tab - the probably played a role in the affected memory calculations.
The next unusual thing about the loop in main at roofline.cpp:247: The bottom orange dot representing it on the Roofline chart is positioned barely above the Scalar Add Peak roofline.
The probable reason: The loop is vectorized inefficiently.
How can we verify this?
In the Survey Report, check the value in the Vectorized Loops/Efficiency: 31%. Vectorization is not enough for a loop to rise to the Vector Add Peak roofline; a loop must be efficiently vectorized.
Why is the Efficiency value so low?
One probable reason: Inefficient memory accesses preventing full utilization of VPU/SIMD resources. Array of Structures (AOS) data layouts often cause this sort of problem. Check the Memory Access Patterns Report.
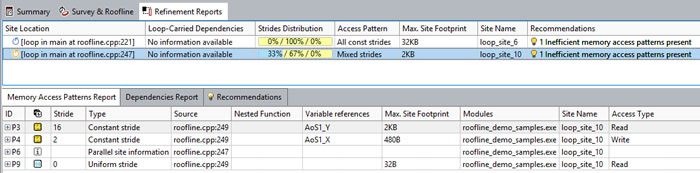
Memory access problem confirmed: The majority of memory accesses are not uniform stride. (The presence of insert operations, as noted in the Code Analytics tab, confirms this.) This contributes to vectorization inefficiency.
How can we improve vectorization efficiency?
Reorganizing code to use Structure of Arrays (SOA) data layout instead of Array of Structures (AOS) data layout is a possible optimization technique. In fact, this is one of the Recommendations the Intel Advisor offers to guide developers seeking optimization advice:
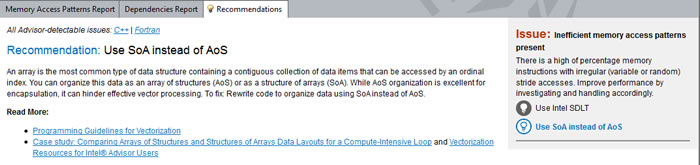
Of course, this is exactly what we did with the loop in main at roofline.cpp:260 (middle orange dot).
Notice the dot is positioned just under the Vector Add Peak roofline. In the Survey Report, check the Vectorize Loops/Efficiency: 100%.
The dot also skipped a memory bandwidth roofline because, as our familiarity with the sample code tells us, it was never limited by L3 cache, and only partially limited by L2 cache.
So switching the data layout to SOA fixed both the compute capacity and memory bandwidth bottlenecks.
Finally, take a look at the loop in main at roofline.cpp:273 - the top orange dot. See if you can figure out why it is positioned above the Vector Add Peak roofline. Hint: In the Assembly tab, compare the instructions for the two loops represented by the top and middle orange dots.