An Open, Standards-Based, Cross-Architecture Programming Solution
Software developers know the challenges of programming across multiple types of data-centric hardware, particularly with the number of accelerator architectures on the market today. The oneAPI industry initiative was created to meet those challenges. Based on open standards, oneAPI is open for contribution and use. A key goal of oneAPI is to remove development barriers that stand in the way of writing software across disparate accelerator architectures. The aim is to enable code to become functional quickly on any architecture by providing common language and APIs that are available everywhere, and critically, to also enable per-architecture analysis and tuning to achieve peak performance.
At the heart of the oneAPI initiative is a programming language called Data Parallel C++ (DPC++) that extends C++ and SYCL1 (developed by The Khronos* Group1). DPC++ provides a consistent programming language across CPU, GPU, FPGA, and AI accelerators in a heterogeneous framework where each architecture can be programmed and used either in isolation, or together. The common language and APIs allow developers to learn once and then program for different accelerators. Each class of accelerator still requires appropriate formulation and tuning of algorithms, but the language in which that development and tuning is done remains consistent regardless of the target device.
DPC++ should be thought of both as a language implementation based on standards, as well as a proving ground for new features proposed for those standards. This approach is commonplace: proof points are generally expected before new features are included in a standard. This provides confidence that the features are implementable, useful, and well-designed in practice. The composition of DPC++ can be understood through the equation:
DPC++ = ISO C++ + Khronos SYCL + extensions
The extensions are feature proof-points that run ahead of standards. An explicit goal of DPC++ is that the extensions, once proven, will be proposed to the parent specifications (SYCL or C++). DPC++ is not intended to diverge from SYCL or C++, but rather to feed into them with proven new features.
The language and API extensions in DPC++ enable different development use cases, all of which are supported and considered for feature design. These uses include development of new offload acceleration, or heterogeneous compute applications, conversion of existing C or C++ code to SYCL and DPC++, and migrating from other accelerator languages or frameworks. DPC++ also is designed to enable heterogeneous frameworks to layer on top, allowing it to act as a backend and coexist in heterogeneous solutions.
Intel is deeply involved in the development of both DPC++ and SYCL, and we are committed to building an open source implementation, upstreaming directly into the community LLVM project. The DPC++ open source project went live on GitHub in January 2019, with active development since, including many contributions from companies and contributors besides Intel. The open source toolchain is based on the Clang and LLVM projects.
By design, the DPC++ language is setup to support multiple vendors’ hardware, giving developers the freedom to choose among a range of performance and price-point options without single vendor lock-in. The standards-based approach and open source implementation help give developers confidence in long-term access to a wide range of hardware targets. DPC++ currently supports hardware including Intel CPUs, GPUs, and FPGAs. Codeplay has even announced a DPC++ compiler that targets Nvidia* GPUs2.
DPC++ and SYCL are designed to operate as a programming abstraction on top of lower level standards and interfaces, including OpenCL™3. This design enables a large deployment base on existing software and driver stacks and interoperability with those lower-level stacks when desired. For example, the beta implementation of DPC++ is designed to execute on any OpenCL 1.2 implementation that supports SPIR-V (in some cases with Intel extensions for newer features). Consider running DPC++ on top of your varied targets and give us your feedback via the oneAPI open project to help improve the diverse backend experience.
A Closer Look at DPC++
The DPC++ language inherits the programmer productivity benefits and familiar constructs of C++, and it incorporates SYCL for cross-architecture support for data parallelism and heterogeneous programming (Figure 1).
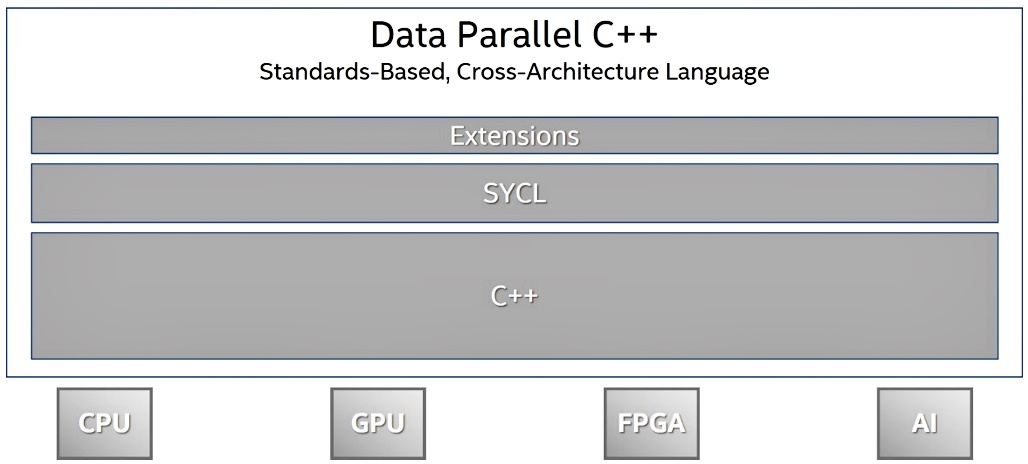
Figure 1. DPC++ is based on C++ and incorporates SYCL (developed by The Khronos Group, Inc.) plus open extensions for development across XPU architectures.
A Kernel-Based Model, Ordered Within and Across XPUs using Task Graphs
SYCL, and therefore DPC++, provides a single-source programming model that lets programmers mix in a single source file the code that will run on accelerators with the code that will run on the host processor (typically to orchestrate the work done by accelerators). Single-source programming makes getting started easier, and it can provide type-safety and optimization advantages in larger-scale applications.
A kernel is the code that will execute on an accelerator. The code typically executes many times per kernel invocation across an ND-Range (the space of work-items in 1-, 2- or 3-dimensional iteration space). Each instance operates on different data. Kernels are clearly identifiable in code. The developer selects the target device or devices on which a kernel will run through the queue to which they submit the kernel for execution. A small number of classes defined by SYCL define a kernel’s execution style (for example, parallel_for).
Kernels can be defined in multiple ways, including:
- C++ lambda (often a thin wrapper calling a function)
- Functor (a C++ class that acts like a function)
- Interoperability kernel with a specific backend (e.g., OpenCL cl_kernel object)

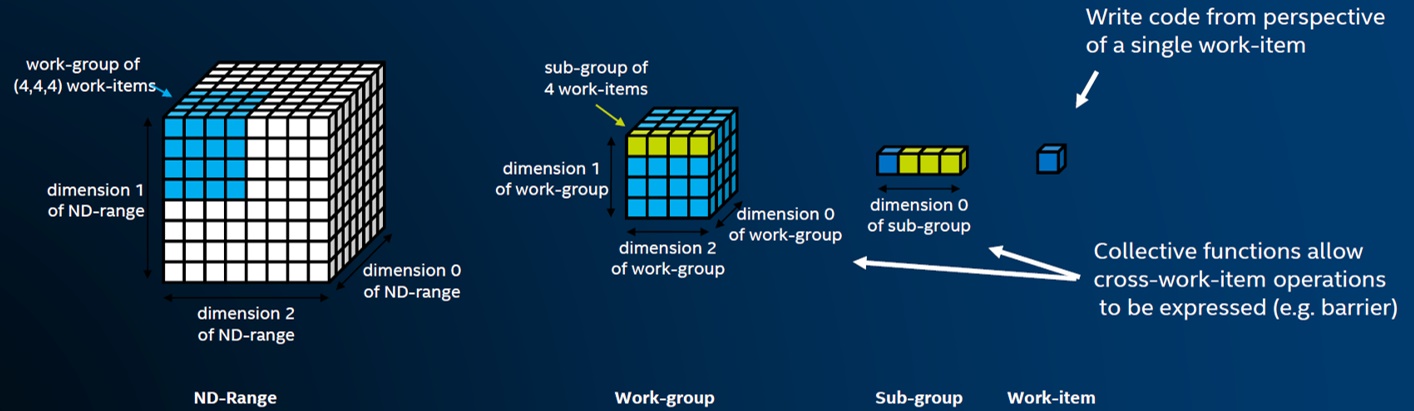
Figure 2. A bottom up, hierarchical, single program multiple data (SPMD) model
DPC++ programs are C++ programs that introduce abstractions such as queue, buffer, and device to add functionality to
- Target specific accelerator devices with work
- Manage data
- Control parallelism
For example, work in the form of a kernel is submitted to a queue, which is a class defined by SYCL that is associated with exactly one device (e.g., a specific GPU or FPGA). Developers can decide which single device a queue is associated with when constructing it, and they can have as many queues as desired for dispatching work in heterogeneous systems (Figure 3).
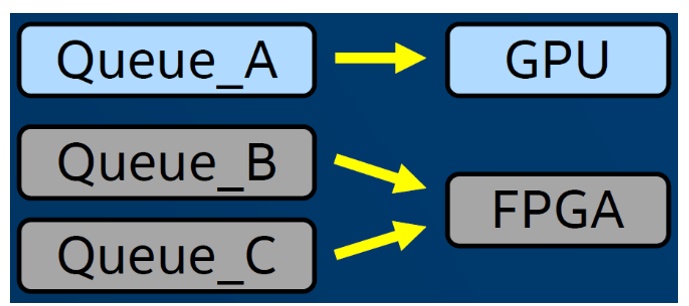
Figure 3. Queues dispatch work in heterogeneous systems.
Kernels are submitted to queues, which define where a kernel should execute. But when is a kernel safe to execute? SYCL defines a task graph abstraction for that. Task graphs (Figure 4) automate the mechanics of data movement, which:
- Significantly reduces the code that must be written in many applications
- Adapts data movement and synchronization across devices and interconnect buses without modification of the program
- Can be overridden for the rare case where a user wants to explicitly manage data motion
Dependencies and ordering of kernel executions are typically driven by uses of data within a kernel, using an abstraction known as a data accessor.
For example, the code shown below leads to this task execution graph, including the dependence edges that determine the ordering of kernel executions.
Kernels are launched by the runtime system when it is safe to do so, without any code or developer action to ensure correct ordering. This powerful abstraction makes it much faster to write applications, and it can transparently adapt to different system topologies.


Figure 4. The task execution graph orders kernel executions.
Data Access Models
There are two general mechanisms in DPC++ to encapsulate and manage access to data:
- The SYCL buffer abstraction encapsulates data in a buffer object which is accessible across devices and the host system—accessors provide a mechanism to access the data within a buffer, creating dependence edges within the task graph and providing a handler to reference/use the buffer’s data;
- The DPC++ Unified Shared Memory (USM) extension enables direct pointer-based programming. It can be very useful when converting existing C++ code to a heterogeneous application running on accelerators, and when data structures require a unified virtual address space across both host and devices (e.g., for a linked list that is traversable on both host and device). A future blog will cover USM in more depth.
The Task Graph is Asynchronous
An important aspect of the DPC++ programming model is that the host program doesn’t stop executing to wait for the kernel to finish (or even start) executing on a device. Instead, the host program simply submits work to queues and carries on executing unless the developer explicitly asks for synchronization with something that is happening on the device. For example, in the code show in Figure 5, the kernel is submitted to a queue for execution on a device, and the host program carries on executing the code after the submission.
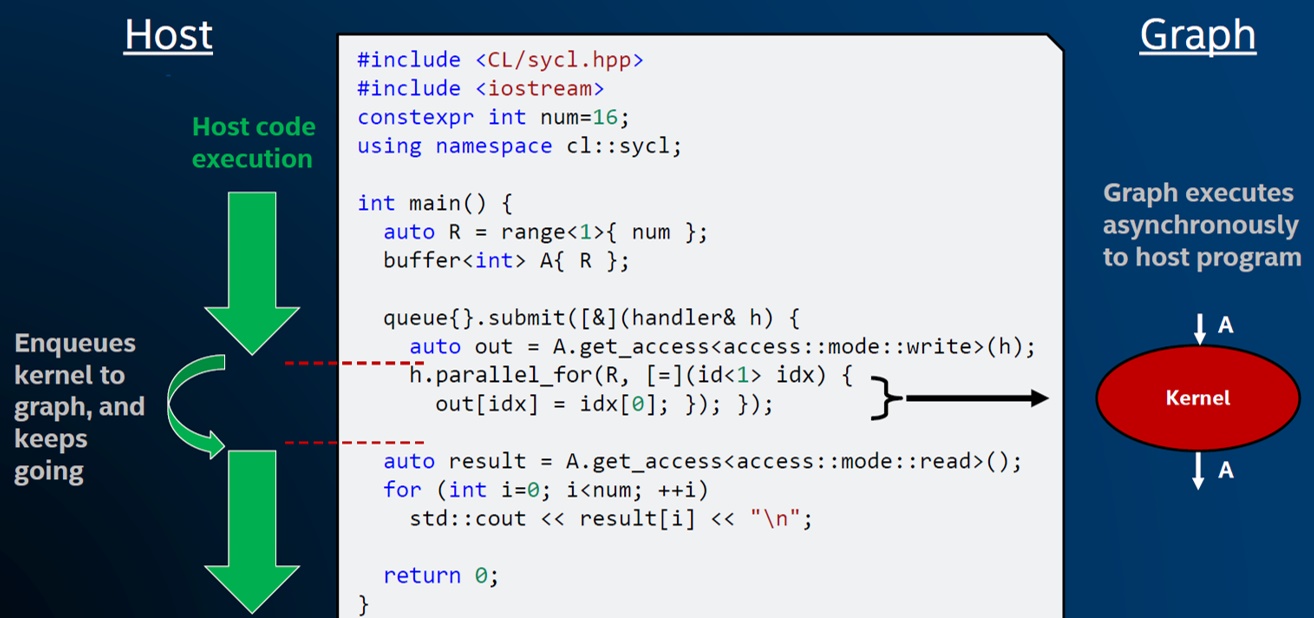
Figure 5. The host code submits work to build the graph. The graph of kernel executions and data movements operates asynchronously from host code, managed by the SYCL runtime.
In this example, the host code will stop and wait at the second call to get_access, because it uses the data that the kernel has produced on a device (streaming it out with std::cout), so it must wait for that kernel to execute and for the data to be moved from device to host. If there wasn’t a get_access call, or something equivalent that would require the host to wait for something that has happened on a device, then the host program continues execution in parallel with executions that are occurring on devices.
DPC++ Extensions to SYCL
A number of DPC++ extensions are defined that run ahead of SYCL as feature proof-points, as described earlier in this article. To provide a flavor of the ongoing work we call out a few examples:
- Unified Shared Memory for pointer-based programming
- Sub-groups that map very efficiently to hardware on SIMD architectures
- Efficient reductions and group algorithms to increase productivity
- Ordered queues to simplify common patterns
- Pipes for efficient compute on spatial and data flow architectures
- Optional lambda naming for reduction of code verbosity
- Simplifications to make common code patterns easy to express
Conclusion
This overview of DPC++ and its relationship to C++ and SYCL briefly introduced some powerful SYCL and DPC++ abstractions. To get started using DPC++, you can access the language and APIs in two ways:
- Intel® DevCloud
- Intel’s reference implementation (Intel® oneAPI Toolkits Beta)
Intel‘s oneAPI software product, which is a set toolkits with advanced tools, is a beta implementation of the oneAPI industry specification including DPC++ . It is available now on the Intel DevCloud to build, test and run your workloads on a variety of Intel® architectures, free of charge.
More Resources
Join the oneAPI Community and Build Your Cross-Architecture Application Today
- Learn about and download Intel® oneAPI Base Toolkit (Base Kit).
- Prototype your project, test code and workloads across a variety of Intel® processors and accelerators in the Intel DevCloud—no downloads, no hardware acquisition, no installation, no set-up and configuration.
Check Out these Additional DPC++ Development Resources
- Get started with the oneAPI Programming Guide
- View the Data Parallel C++: An Open Alternative for Cross-Architecture Development video [12.05] Read the advanced chapters of the upcoming DPC++ book
- Access free oneAPI and DPC++ deep dive webinars and quick how-to’s
- DPC++ Data Management across Multiple Architectures Part 1: Efficient Data Movement and Control Using the oneAPI Programming Framework
- DPC++ Data Management across Multiple Architectures Part 2: Ordering Execution Using the oneAPI Programming Framework
Authors

James Brodman is an Intel software engineer researching languages and compilers for parallel programming. He is currently focused on the oneAPI initiative and DPC++, and he has written extensively on programming models for SIMD/vector processing, languages for parallel processing, distributed memory theory & practice, programming multi-core systems, and more.

Mike Kinsner is an Intel software engineer working on parallel programming models for a variety of architectures, and high-level compilers for spatial architectures. He is an Intel representative within The Khronos Group where he contributes to the SYCL™ and OpenCL™ industry standards, and is currently focused on DPC++ within the oneAPI initiative.
Footnotes
1Khronos is a registered trademark, and SYCL and SPIR-V are trademarks of the Khronos Group, Inc.
2Codeplay contribution to DPC++ brings SYCL support for NVIDIA GPUs, February 3, 2020
3OpenCL and the OpenCL logo are trademarks of Apple Inc., used by permission by the Khronos Group, Inc.
Copyright Intel® Corporation. Intel and the Intel logo are registered trademarks of Intel Corporation. All other trade names may be claimed as property by others.
Intel's compilers may or may not optimize to the same degree for non-Intel microprocessors for optimizations that are not unique to Intel microprocessors. These optimizations include SSE2, SSE3, and SSSE3 instruction sets and other optimizations. Intel does not guarantee the availability, functionality, or effectiveness of any optimization on microprocessors not manufactured by Intel. Microprocessor-dependent optimizations in this product are intended for use with Intel microprocessors. Certain optimizations not specific to Intel microarchitecture are reserved for Intel microprocessors. Please refer to the applicable product User and Reference Guides for more information regarding the specific instruction sets covered by this notice.
Intel technologies may require enabled hardware, software or service activation. No product or component can be absolutely secure. Your costs and results may vary.
Intel does not control or audit third-party data. You should consult other sources to evaluate accuracy.
Intel disclaims all express and implied warranties, including without limitation, the implied warranties of merchantability, fitness for a particular purpose, and non-infringement, as well as any warranty arising from course of performance, course of dealing, or usage in trade.
© Intel Corporation. Intel, the Intel logo, and other Intel marks are trademarks of Intel Corporation or its subsidiaries. Other names and brands may be claimed as the property of others.