We demonstrate how to create a Sierpiński Carpet in OpenCL* 2.0
Prerequisites:
A laptop or a workstation with the 5th Generation Intel® Core™ Processor
- OpenCL™ Drivers and Runtimes for Intel® Architecture
- Intel® SDK for OpenCL™ Applications
- Intel® VTune™ Amplifier XE 2013 (Optional)
- Intel Processor Graphics
What is Nested Parallelism?
Device kernels can enqueue kernels to the same device with no host interaction, enabling flexible work scheduling paradigms and avoiding the need to transfer execution control and data between the device and host, often significantly offloading host processor bottlenecks (see Khronos Finalizes OpenCL 2.0 Specification for Heterogeneous Computing).
What are Blocks?
Blocks simplify nested parallelism (also known as device-side enqueue). 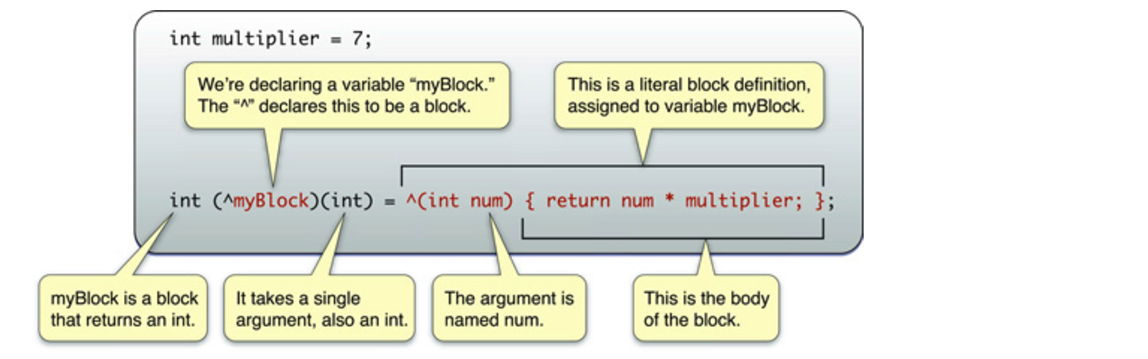
For more information see Blocks in OpenCL 2.0.
What is Sierpiński Carpet?
The Sierpiński carpet is a plane fractal first described by Wacław Sierpiński in 1916. Start with a white square. Divide the square into 9 sub-squares in a 3-by-3 grid. Paint the central sub-square black. Apply the same procedure recursively to the remaining 8 sub-squares. And so on …
See http://en.wikipedia.org/wiki/Sierpinski_carpet for more info.

enqueue_kernel API
int enqueue_kernel ( queue_t queue,
kernel_enqueue_flags_t flags,
const ndrange_t ndrange,
void (^block)(void) );
Sierpiński Carpet – Host Side
// You need to create device side queue for enqueue_kernel to work
// We set the device side queue to 16MB,
// since we are going to have a large number of enqueues
cl_queue_properties qprop[] = {CL_QUEUE_SIZE, 16*1024*1024,
CL_QUEUE_PROPERTIES,
(cl_command_queue_properties)CL_QUEUE_OUT_OF_ORDER_EXEC_MODE_ENABLE |
CL_QUEUE_ON_DEVICE |
CL_QUEUE_ON_DEVICE_DEFAULT, 0};
cl_command_queue my_device_q = clCreateCommandQueueWithProperties(CLU_CONTEXT, cluGetDevice(CL_DEVICE_TYPE_GPU), qprop, &status);
Sierpiński Carpet in OpenCL 2.0
__kernel void sierpinski(__global char* src, int width, int offsetx, int offsety)
{
int x = get_global_id(0);
int y = get_global_id(1);
queue_t q = get_default_queue();
int one_third = get_global_size(0) / 3;
int two_thirds = 2 * one_third;
if (x >= one_third && x < two_thirds &&
y >= one_third && y < two_thirds)
{
src[(y+offsety)*width+(x+offsetx)] = BLACK;
}
else
{
src[(y+offsety)*width+(x+offsetx)] = WHITE;
if (one_third > 1 && x % one_third == 0 && y % one_third == 0)
{
const size_t grid[2] = {one_third, one_third};
enqueue_kernel(q, 0, ndrange_2D(grid), ^{ sierpinski (src, width, x+offsetx, y+offsety); });
}
}
}
Download the full source code of the sample below.
About the Author
Robert Ioffe is a Technical Consulting Engineer at Intel’s Software and Solutions Group. He is an expert in OpenCL programming and OpenCL workload optimization on Intel Iris and Intel Iris Pro Graphics with deep knowledge of Intel Graphics Hardware. He was heavily involved in Khronos standards work, focusing on prototyping the latest features and making sure they can run well on Intel architecture. Most recently he has been working on prototyping Nested Parallelism (enqueue_kernel functions) feature of OpenCL 2.0 and wrote a number of samples that demonstrate Nested Parallelism functionality, including GPU-Quicksort for OpenCL 2.0. He also recorded and released two Optimizing Simple OpenCL Kernels videos and is in the process of recording a third video on Nested Parallelism.
You might also be interested in the following:
GPU-Quicksort in OpenCL 2.0: Nested Parallelism and Work-Group Scan Functions
Optimizing Simple OpenCL Kernels: Modulate Kernel Optimization
Optimizing Simple OpenCL Kernels: Sobel Kernel Optimization