1 Introducing Packed APIs for GEMM
Matrix-matrix multiplication (GEMM) is a fundamental operation in many scientific, engineering, and machine learning applications. There is a continuing demand to optimize this operation, and Intel® Math Kernel Library (Intel® MKL) offers parallel high-performing GEMM implementations. To provide optimal performance, the Intel MKL implementation of GEMM typically transforms the original input matrices into an internal data format best suited for the targeted platform. This data transformation (also called packing) can be costly, especially for input matrices with one or more small dimensions.
Intel MKL 2017 introduces [S,D]GEMM packed application program interfaces (APIs) that allow users to explicitly transform the matrices into an internal packed format and pass the packed matrix (or matrices) to multiple GEMM calls. With this approach, the packing costs can be amortized over multiple GEMM calls if the input matrices (A or B) are reused between these calls.
Note that Intel MKL 2017 introduces [S,D]GEMM_ALLOC and [S,D]GEMM_FREE, those functions have been deprecated in MKL 2019 update 1 also introducing [S,D]GEMM_PACK_GET_SIZE.
2 Example
Three GEMM calls shown below use the same A matrix, while B/C matrices differ for each call:
float *A, *B1, *B2, *B3, *C1, *C2, *C3, alpha, beta;
MKL_INT m, n, k, lda, ldb, ldc;
// initialize the pointers and matrix dimensions (skipped for brevity)
sgemm(“T”, “N”, &m, &n, &k, &alpha, A, &lda, B1, &ldb, &beta, C1, &ldc);
sgemm(“T”, “N”, &m, &n, &k, &alpha, A, &lda, B2, &ldb, &beta, C2, &ldc);
sgemm(“T”, “N”, &m, &n, &k, &alpha, A, &lda, B3, &ldb, &beta, C3, &ldc);
Here the A matrix is transformed into internal packed data format within each sgemm call. The relative cost of packing matrix A three times can be high if n is small (number of columns for B/C). This cost can be minimized by packing the A matrix once and using its packed equivalent for the three consecutive GEMM calls as shown below:
// allocate memory for packed data format
float *Ap;
size_t Ap_size = sgemm_pack_get_size(“A”, &m, &n, &k);
Ap = (float *)mkl_malloc(Ap_size, 64);
// transform A into packed format
sgemm_pack(“A”, “T”, &m, &n, &k, &alpha, A, &lda, Ap);
// SGEMM computations are performed using the packed A matrix: Ap
sgemm_compute(“P”, “N”, &m, &n, &k, Ap, &lda, B1, &ldb, &beta, C1, &ldc);
sgemm_compute(“P”, “N”, &m, &n, &k, Ap, &lda, B2, &ldb, &beta, C2, &ldc);
sgemm_compute(“P”, “N”, &m, &n, &k, Ap, &lda, B3, &ldb, &beta, C3, &ldc);
// release the memory for Ap
mkl_free(Ap);
The code sample above uses three new functions introduced to support packed APIs for GEMM: sgemm_pack_get_size, sgemm_pack and sgemm_compute. First, the size in bytes required for packed format is queried using sgemm_pack_get_size, which accepts a character argument identifying the packed matrix (A in this example) and three integer arguments for the matrix dimensions. Then, buffer for the packed matrix is allocated using mkl_malloc and sgemm_pack transforms the original A matrix into the packed format Ap and performs the alpha scaling. The original A matrix remains unchanged. The three sgemm calls are replaced with three sgemm_compute calls that work with packed matrices and assume that alpha=1.0. The first two character arguments to sgemm_compute indicate that the A matrix is in packed format (“P”), and the B matrix is in non-transposed column major format (“N”). Finally, the memory allocated for Ap is released by calling mkl_free.
GEMM packed APIs eliminate the cost of packing the matrix A twice for the three matrix-matrix multiplication operations shown in this example. These packed APIs can be used to eliminate the data transformation costs for A and/or B input matrices if A and/or B are re-used between GEMM calls.
3 Performance
The chart below shows the performance gains with the packed APIs on Intel® Xeon Phi™ Processor 7250. It is assumed that the packing cost can be completely amortized by a large number of SGEMM calls that use the same A matrix. The performance of regular SGEMM calls is also provided for comparison.
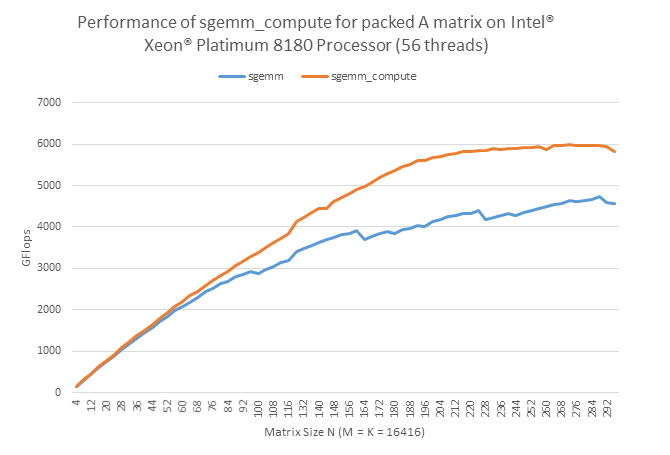
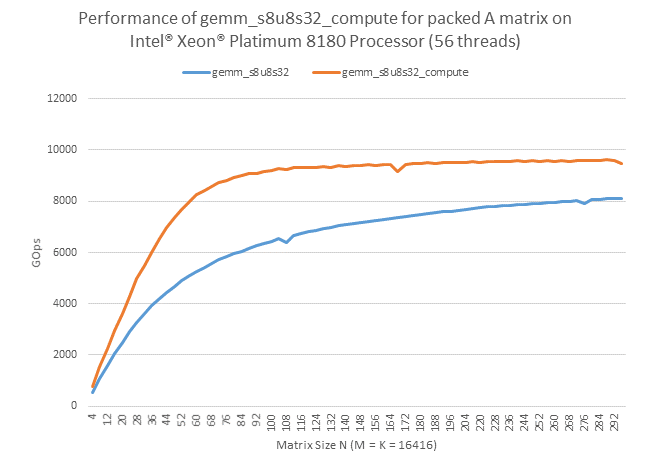
4 Implementation Notes
It is recommended to call gemm_pack and gemm_compute with the same number of threads to get the best performance. Note that if there are only a small number of GEMM calls that share the same A or B matrix, the packed APIs may provide little performance benefit.
The size needed to store the packed matrix is approximately as large as the original input matrix. This means that the memory requirement of the application may increase significantly for a large input matrix.
GEMM packed APIs are only implemented for SGEMM and DGEMM in Intel MKL 2017. The Intel MKL 2019 update 1 introduces GEMM packed APIs for integer GEMM as well. They are functional for all Intel architectures, but they are only optimized for 64-bit Intel® AVX2 and above.
5 Summary
[S,D]GEMM packed APIs can be used to minimize the data packing costs for multiple GEMM calls that use the same input matrix. As shown in the performance chart, calling them can improve the performance significantly if there is sufficient matrix reuse across multiple GEMM calls. These packed APIs are available in Intel MKL 2017, and both FORTRAN 77 and CBLAS interfaces are supported. Please see the Intel MKL Developer Reference for additional documentation.
