Today, we are excited to see Meta release Llama 2, to help further democratize access to LLMs. Making such models more widely available will facilitate efforts across the AI community to benefit the world at large.
Large Language Models (LLMs) offer one of the most promising AI technologies to benefit society at scale given the remarkable capability they have demonstrated in generating text, summarizing and translating content, responding to questions, engaging in conversations, and performing complex tasks such as solving math problems or reasoning. LLMs have the potential to unlock new forms of creativity and insights, as well as inspire passion in the AI community to advance the technology.
Llama 2 is designed to enable developers, researchers, and organizations to build generative AI-powered tools and experiences. Meta released pretrained and fine-tuned versions of Llama 2 with 7B, 13B, and 70B parameters. With Llama 2, Meta implemented three core safety-oriented techniques across the company’s fine-tuned models: supervised safety fine-tuning, targeted safety context distillation, and safety reinforcement learning from human feedback (RLHF). Those combined have enabled Meta to improve safety performance. By democratizing access, it allows continual identification and mitigation of vulnerabilities in a transparent and open manner.
Intel is committed to democratizing AI with ubiquitous hardware and open software. Intel offers a portfolio of AI solutions that provide competitive and compelling options for the community to develop and run models like Llama 2. Intel’s rich AI hardware portfolio combined with optimized open software provides alternatives to mitigate the challenge of accessing limited compute resources.
“Intel provides AI optimization software for model development and deployment. The open ecosystem is inherent to Intel’s strategy, and AI is no different. It is critical as an industry that we lean into creating a vibrant open ecosystem for AI innovation, ensuring security, traceability, responsibility, and ethics. This announcement furthers our core values of openness, enabling developer choice and trust. The release of the Llama 2 models is an important step in our industry’s transformation to open AI development ensuring innovation continues to thrive through transparency.”
Wei Li, VP Software and Advanced Technology, GM of AI & Analytics
Melissa Evers, VP Software and Advanced Technology, GM of Strategy to Execution
At release of Llama 2, we are happy to share initial inference performance results for 7 billion and 13 billion parameter models on Intel’s AI portfolio, including Habana® Gaudi®2 deep learning accelerator, 4th Gen Intel® Xeon® Scalable processor, Intel® Xeon® CPU Max Series, and Intel® Data Center GPU Max. The performance metrics we share in this blog provide out of box performance with our currently released software with additional performance gains expected in upcoming releases. We are also enabling the 70 billion parameter model and will share an update soon to help keep the community informed.
Habana® Gaudi®2 Deep Learning Accelerator
Habana Gaudi2 is designed to provide high-performance, high-efficiency training and inference, and is particularly well-suited for large language models, such as Llama and Llama 2. Each Gaudi2 accelerator features 96 GB of on-chip HBM2E to meet the memory demands of large language models, thus accelerating inference performance. Gaudi2 is supported by the Habana® SynapseAI® software suite, which integrates PyTorch and DeepSpeed for both training and inference of LLMs. Moreover, support for HPU Graphs and DeepSpeed inference have recently been introduced in SynapseAI, and these are well-suited for latency-sensitive inference applications. Further software optimizations are coming to Gaudi2, including support for the FP8 data type in Q3 2023, which is expected to deliver substantial performance boosts, increasing throughput and reducing latency in LLM execution.
Performance on LLMs requires flexible and nimble scalability to reduce networking bottlenecks, both within the server and across nodes. Every Gaudi2 integrates 24 100 Gigabit Ethernet ports; 21 ports can be dedicated to all-to-all connectivity to the eight Gaudi2s within the server and three ports per Gaudi2 dedicated to scale out. This network configuration helps to accelerate scaled performance both within and beyond the server.
Gaudi2 has demonstrated excellent training performance on large language models on the recently published MLPerf benchmark for training the 175 billion parameter GPT-3 model on 384 Gaudi2 accelerators. For more information on these results see the recent Intel Newsroom article. This proven performance on Gaudi2 makes it a highly effective solution for both training and inference of Llama and Llama 2.
In Figure 1, we share the inference performance of the Llama 2 7B and Llama 2 13B models, respectively, on a single Habana Gaudi2 device with batch size of 1, output token length of 256 and various input token lengths, using mixed precision (BF16). The performance metric reported is the latency per token (excluding the first token). The optimum-habana text generation script was used to run inference on the Llama models. The optimum-habana library makes it simple and easy to deploy these models with minimal code changes on Gaudi accelerators. In Figure 1, we see that for 128 – 2K input tokens, Gaudi2 inference latency for the 7B model ranges from 9.0 -12.2 milliseconds per token, while for the 13B model, it ranges from 15.5 – 20.4 milliseconds per token1.
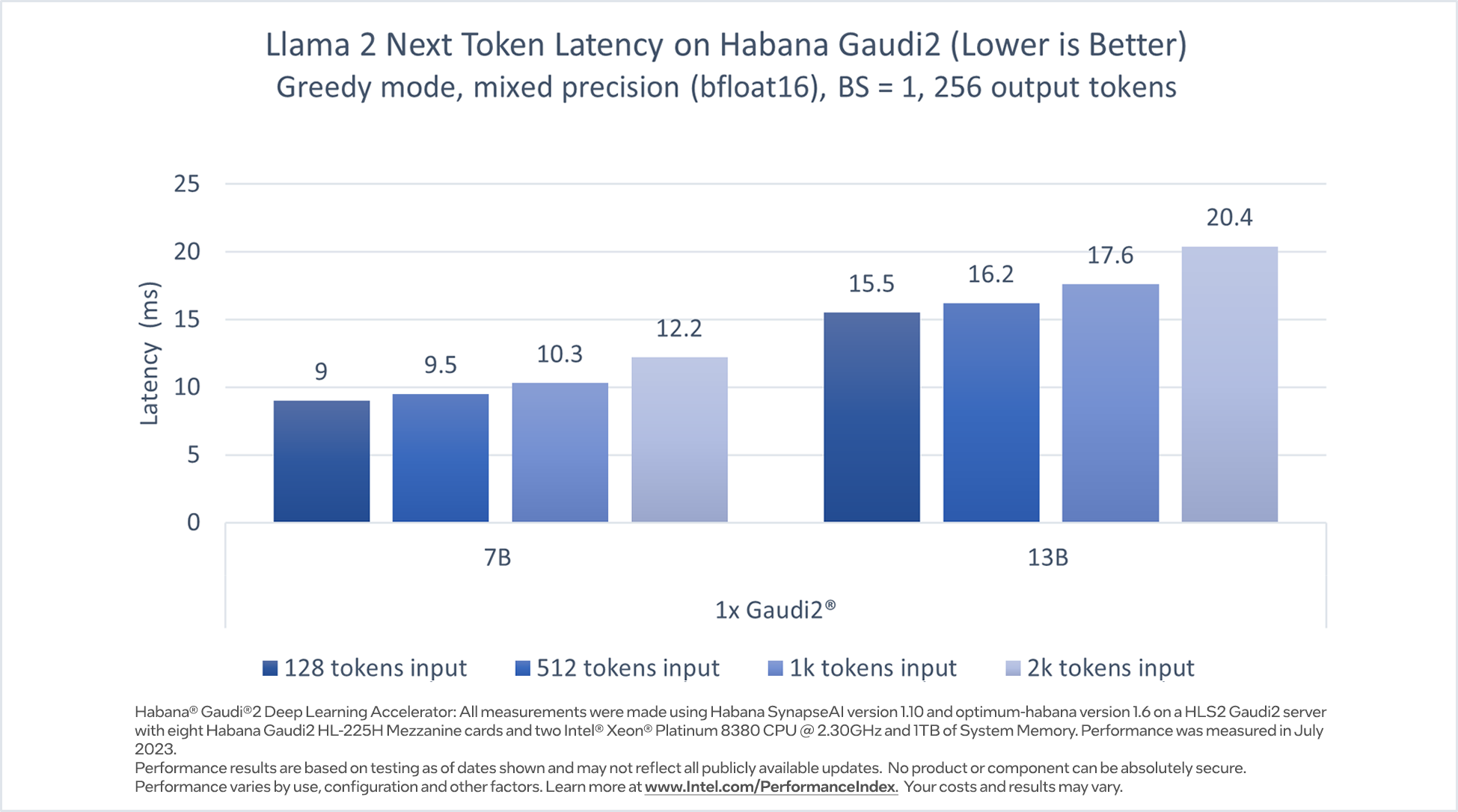
Figure 1. Llama 2 7B and 13B inference performance on Habana Gaudi2
Get started on your Generative AI journey with Llama 2 on Habana Gaudi platform today. If you would like to get access to Gaudi2, sign up for an instance on the Intel Developer Cloud following the instructions here or contact Supermicro regarding Gaudi2 Server infrastructure.
Intel® Xeon® Scalable Processor
The 4th gen Intel Xeon Scalable processors are general purpose compute with AI infused acceleration known as Intel® Advanced Matrix Extensions (Intel® AMX). Specifically, it has built-in BF16 and INT8 GEMM (general matrix-matrix multiplication) accelerators in every core to accelerate deep learning training and inference workloads. In addition the Intel® Xeon® CPU Max Series offers 128GB of high-bandwidth memory (HBM2E) across two sockets, which is beneficial for LLMs because the workload is often memory-bandwidth bound.
Software optimizations for Intel Xeon processors have been upstreamed into deep learning frameworks and are available in the default distributions of PyTorch*, TensorFlow*, DeepSpeed* and other AI libraries. Intel leads the development and optimization of the CPU backend of torch.compile, which is a flagship feature in PyTorch 2.0. Intel also offers Intel® Extension for PyTorch* to stage the advanced optimizations for Intel CPUs before they are upstreamed into the official PyTorch distribution.
Intel 4th Gen Xeon’s higher memory capacity enables low latency LLM execution within a single socket, which is applicable for conversational AI and text summarization applications. This evaluation highlights the latency of executing 1 model per single socket for BF16 and INT8. Intel Extension for PyTorch* has enabled support of SmoothQuant to secure good accuracy with INT8 precision models.
Considering that LLM applications need to generate tokens fast enough to satisfy the reading speed of a fast reader, we chose token latency (time to generate each token) as the major performance metric to report, and, as a reference, the reading speed of a fast human reader, which translates to ~100ms per token. Figures 2 and 3 show that Intel 4th Gen Xeon single socket delivers latencies under 100ms for Llama 2 7B BF16 model and Llama 2 13B INT8 model2.
Intel Xeon CPU Max Series delivers lower latency for both models benefiting from the HBM2E higher bandwidth. With Intel AMX acceleration, users can improve the throughput with higher batch size.
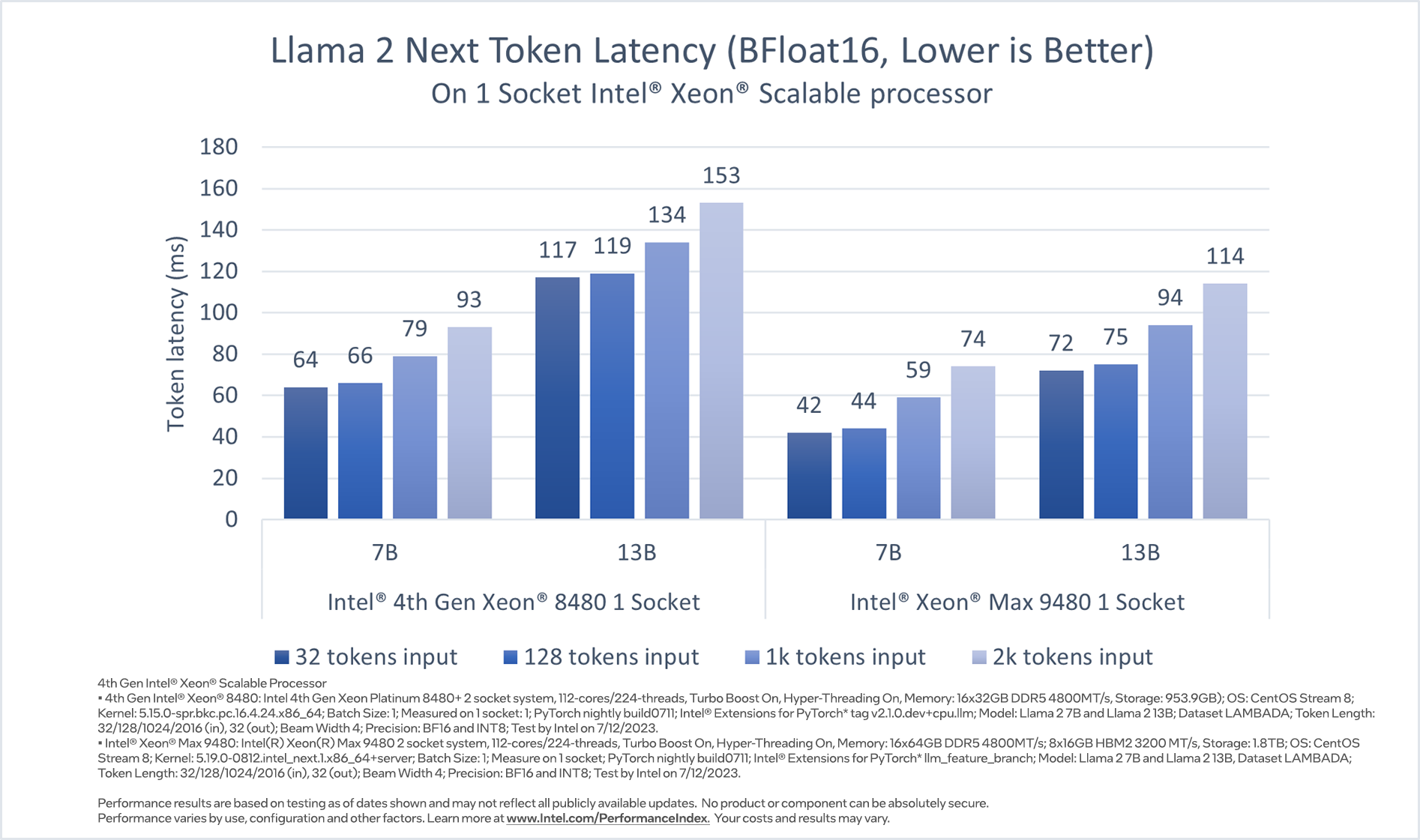
Figure 2. Llama 2 7B and 13B inference (BFloat16) performance on Intel Xeon Scalable Processor
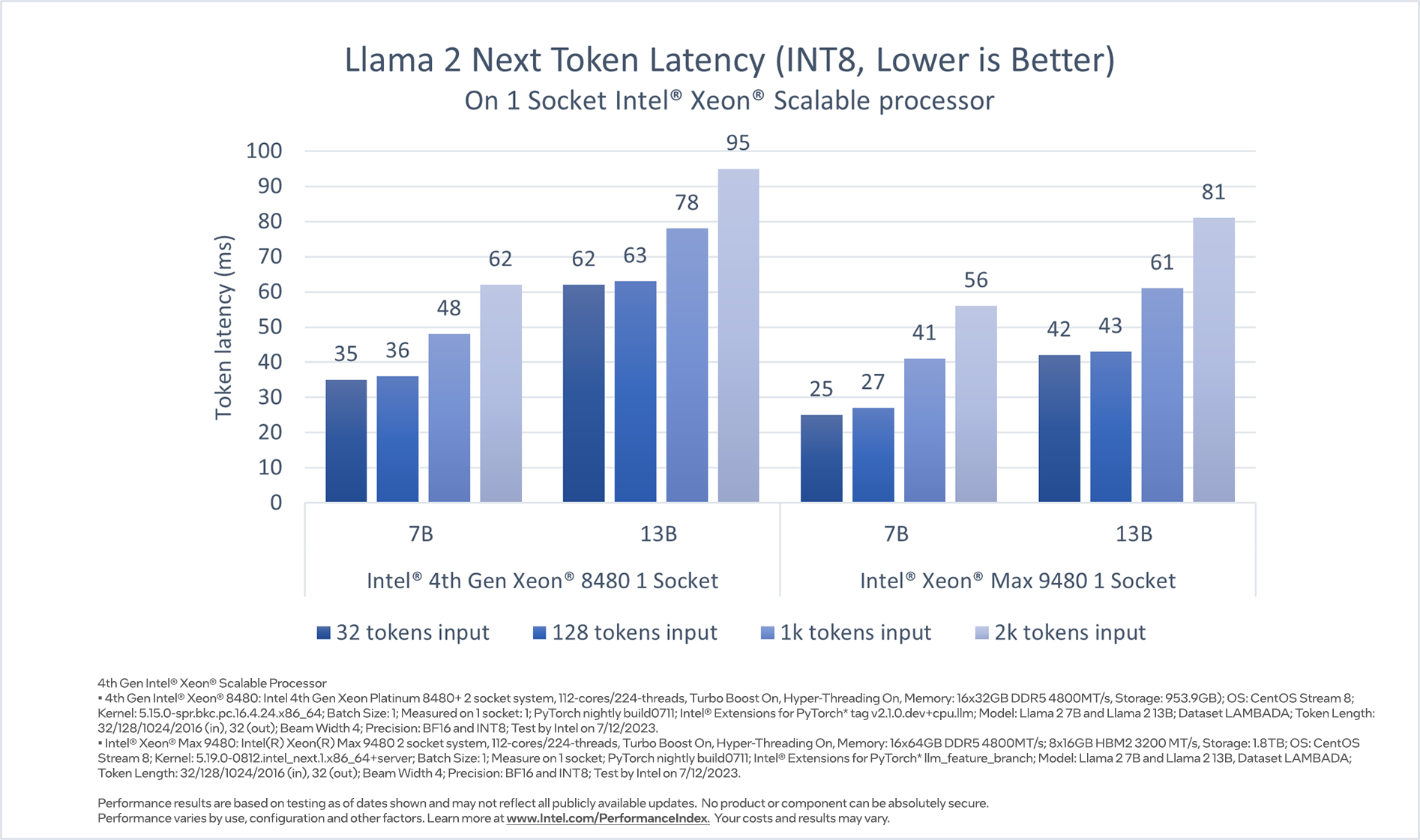
Figure 3. Llama 2 7B and 13B inference (INT8) performance on Intel Xeon Scalable Processor
One 4th Gen Xeon socket delivers latencies under 100ms with 7 billon parameter and 13 billon parameter size of models. Users can run 2 parallel instances, one on each socket, for higher throughput and to serve clients independently. Alternatively, users can leverage Intel Extension for PyTorch* and DeepSpeed* CPU to run inference on both 4th Gen Xeon sockets using tensor parallelism and further reduce the latency or to support larger models.
Developers can get more details about running LLMs and Llama 2 on Xeon platforms here. The cloud instances of 4th Gen Intel Xeon Scalable processor are available for preview on Amazon Web Services and Microsoft Azure, and for general availability on Google Cloud Platform and Ali Cloud. Intel will continue adding software optimizations to PyTorch* and DeepSpeed* to further accelerate Llama 2 and other LLMs.
Intel® Data Center GPU Max Series
Intel Data Center GPU Max delivers parallel compute, HPC, and AI for HPC acceleration. The Intel Data Center GPU Max Series – Intel’s highest performing, highest density discrete GPU, packs over 100 billion transistors into a package and contains up to 128 Xe Cores – is Intel’s foundational GPU compute building block.
Intel Data Center GPU Max Series is designed for breakthrough performance in data-intensive computing models used in AI and HPC including:
- 408 MB of L2 cache based on discrete SRAM technology and 64 MB of L1 cache and up to 128 GB of high-bandwidth memory (HBM2E).
- AI-boosting Xe Intel® Matrix Extensions (Intel® XMX) with systolic arrays enabling vector and matrix capabilities in a single device.
The Intel Max Series family of products are unified by oneAPI for a common, open, standards-based programming model to unleash productivity and performance. Intel oneAPI tools include advanced compilers, libraries, profilers, and code migration tools to easily migrate CUDA code to open C++ with SYCL.
The software enabling and optimizations for Intel Data Center Max GPUs are delivered through the open-source extensions for frameworks today, such as Intel Extension for PyTorch*, Intel® Extension for TensorFlow* and Intel® Extension for DeepSpeed*. By using these extensions together with the upstream framework releases, users will be able to realize drop-in acceleration for machine learning workflows.
The inference performance of Llama 2 7 billion and Llama 2 13 billion parameters models are evaluated on a 600W OAM device which has two GPUs (tiles) on the package, while we only used one of the tiles to run the inference. Figure 4 shows that Intel Data Center GPU Max single tile can deliver less than 20 milliseconds per token latency for inference of 7 billion model and 29.2 – 33.8 milliseconds per token latency for inference of 13 billion parameters models, for input token lengths 32 to 2K tokens 3. Users can run 2 parallel instances, one on each tile, for higher throughput and to serve clients independently.
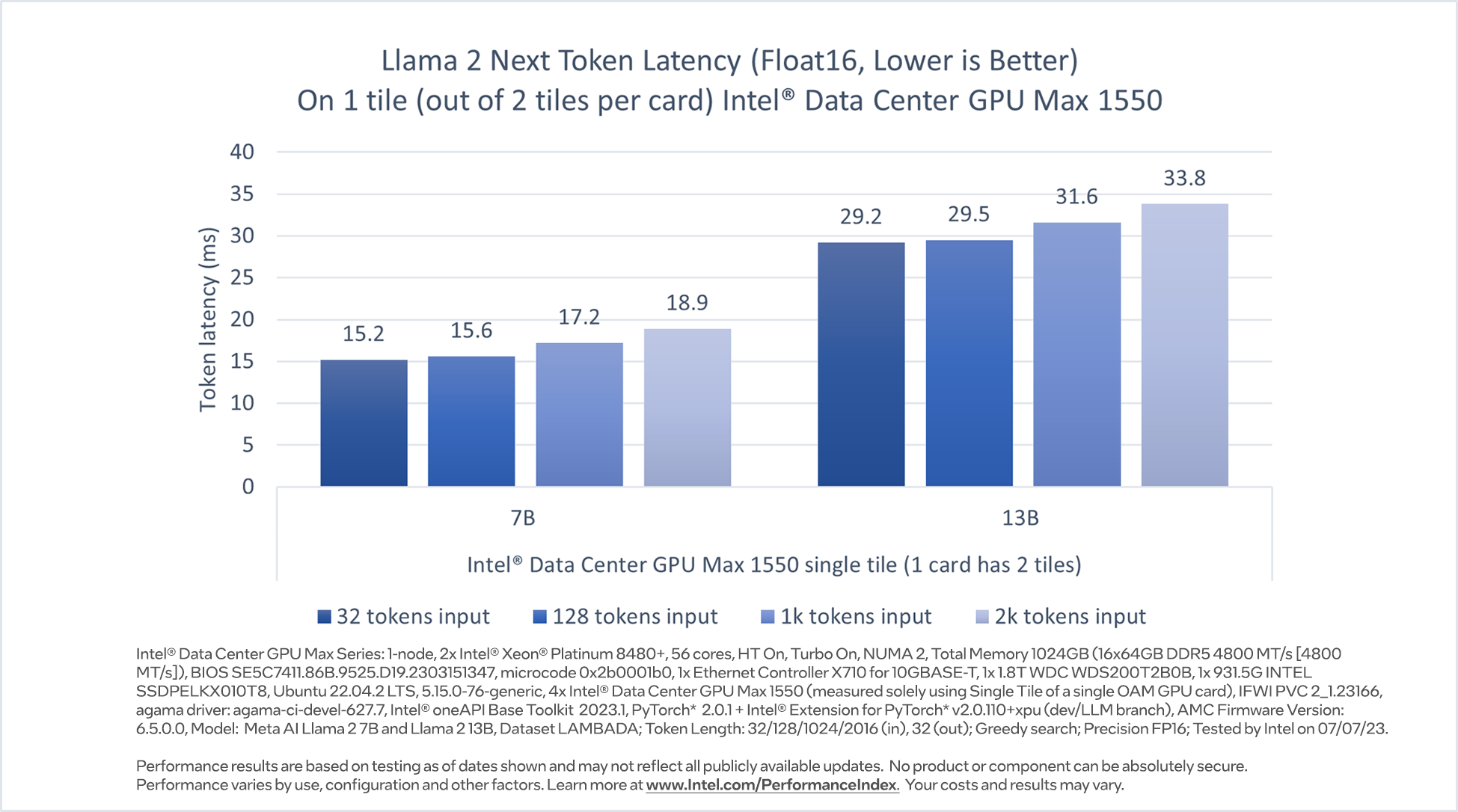
Figure 4. Llama 2 7B and 13B inference performance on Intel Data Center GPU Max 1550
You can get more details about running LLMs and Llama 2 on Intel GPU platforms here. The Intel GPU Max cloud instances available on the Intel Developer Cloud are currently in beta.
LLM Fine-Tuning on Intel Platforms
Besides the inference, Intel has been actively working on the acceleration of fine-tuning through upstreaming the optimizations to Hugging Face Transformers, PEFT, Accelerate, and Optimum libraries, and providing reference workflows in Intel® Extension for Transformers that can support efficient deployment of typical LLM-based tasks, such as text generation, code generation, completion and summarization on supported Intel platforms.
Summary
In this blog, we have presented our initial evaluation of inference performance of Llama 2 7 billion and 13 billion parameter models on Intel’s AI hardware portfolio, including Habana Gaudi2 deep learning accelerator, 4th Gen Intel Xeon Scalable processor, Intel® Xeon® CPU Max Series, and Intel Data Center GPU Max. We are continuing to add optimizations in software releases and will share more evaluations around LLMs and larger Llama 2 models soon.
References
Perform Model Compression Using Intel® Neural Compressor: huggingface/optimum-habana: Easy and lightning fast training of 🤗 Transformers on Habana Gaudi processor (HPU) (github.com)
Developer Tools for Intel® Data Center GPU Max Series
Meta Llama2 paper: https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/
Meta Llama2 blog: https://ai.meta.com/llama/
Product and Performance Information
1 Habana® Gaudi®2 Deep Learning Accelerator: All measurements were made using Habana SynapseAI version 1.10 and optimum-habana version 1.6 on a HLS2 Gaudi2 server with eight Habana Gaudi2 HL-225H Mezzanine cards and two Intel® Xeon® Platinum 8380 CPU @ 2.30GHz and 1TB of System Memory. Performance was measured in July 2023.
2 4th Gen Intel® Xeon® Scalable Processor
- 4th Gen Intel® Xeon® 8480: Intel 4th Gen Xeon Platinum 8480+ 2 socket system, 112-cores/224-threads, Turbo Boost On, Hyper-Threading On, Memory: 16x32GB DDR5 4800MT/s, Storage: 953.9GB); OS: CentOS Stream 8; Kernel: 5.15.0-spr.bkc.pc.16.4.24.x86_64; Batch Size: 1; Measured on 1 socket: 1; PyTorch nightly build0711; Intel® Extensions for PyTorch* tag v2.1.0.dev+cpu.llm; Model: Llama 2 7B and Llama 2 13B; Dataset LAMBADA; Token Length: 32/128/1024/2016 (in), 32 (out); Beam Width 4; Precision: BF16 and INT8; Test by Intel on 7/12/2023.
- Intel® Xeon® Max 9480: Intel(R) Xeon(R) Max 9480 2 socket system, 112-cores/224-threads, Turbo Boost On, Hyper-Threading On, Memory: 16x64GB DDR5 4800MT/s; 8x16GB HBM2 3200 MT/s, Storage: 1.8TB; OS: CentOS Stream 8; Kernel: 5.19.0-0812.intel_next.1.x86_64+server; Batch Size: 1; Measure on 1 socket; PyTorch nightly build0711; Intel® Extensions for PyTorch* llm_feature_branch; Model: Llama 2 7B and Llama 2 13B, Dataset LAMBADA; Token Length: 32/128/1024/2016 (in), 32 (out); Beam Width 4; Precision: BF16 and INT8; Test by Intel on 7/12/2023.
3 Intel® Data Center GPU Max Series: 1-node, 2x Intel® Xeon® Platinum 8480+, 56 cores, HT On, Turbo On, NUMA 2, Total Memory 1024GB (16x64GB DDR5 4800 MT/s [4800 MT/s]), BIOS SE5C7411.86B.9525.D19.2303151347, microcode 0x2b0001b0, 1x Ethernet Controller X710 for 10GBASE-T, 1x 1.8T WDC WDS200T2B0B, 1x 931.5G INTEL SSDPELKX010T8, Ubuntu 22.04.2 LTS, 5.15.0-76-generic, 4x Intel® Data Center GPU Max 1550 (measured solely using Single Tile of a single OAM GPU card), IFWI PVC 2_1.23166, agama driver: agama-ci-devel-627.7, Intel® oneAPI Base Toolkit 2023.1, PyTorch* 2.0.1 + Intel® Extension for PyTorch* v2.0.110+xpu (dev/LLM branch), AMC Firmware Version: 6.5.0.0, Model: Meta AI Llama 2 7B and Llama 2 13B, Dataset LAMBADA; Token Length: 32/128/1024/2016 (in), 32 (out); Greedy search; Precision FP16; Tested by Intel on 07/07/23.
4 Performance varies by use, configuration and other factors. Learn more at www.Intel.com/PerformanceIndex.