Sample 1: Frame Resources Count
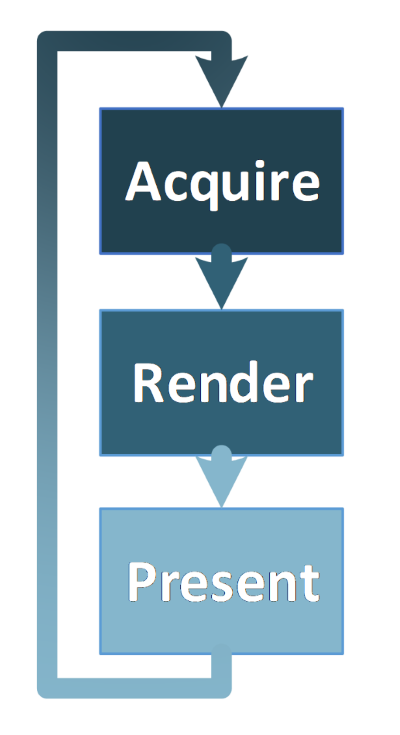
We start with a simple problem: the most general layout of our application. We probably know that Vulkan* applications, which render things on screen, should have more or less the following structure:
- Acquire a swap chain image
- Render into the acquired image
- Present the image on screen
- Repeat the whole process
In order to set up and follow this structure, we need to prepare a set of resources. To render anything, to perform any job, we need at least one command buffer. We want to use it to render our scene into the acquired image. But we cannot start the rendering process until the presentation engine allows us to do so, until the acquired image is ready to be used for rendering. This action is indicated either by a semaphore or by a fence, which we provide when we want to acquire an image. In Vulkan, fences are used to synchronize the CPU (our application) with GPU (graphics hardware); semaphores are used to synchronize the GPU internally. Waiting on the CPU side isn't recommended, as usually this also introduces stalls into the rendering pipeline. We don't want our application to be blocked because we didn't feed the GPU with enough commands. That's why we suggest using semaphores whenever possible.
So, now we already have two of the resources required to render a single frame of animation: a command buffer and a semaphore signaling the moment the GPU can use an image acquired from a swap chain. Now we can record this command buffer and submit it and provide the semaphore—which informs the rendering pipeline when it can start outputting color data to the image. We still cannot display the image on screen, however, because the presentation process must also be synchronized with the rendering process. We cannot present the image until the rendering is done; for this we need another semaphore. This semaphore is signaled when the GPU finishes processing the submitted command buffer. This way, we inform the presentation engine when it can display the image.
The above three resources (the command buffer and two semaphores) may not be all; we may need other resources as well. Usually, when we prepare resources used in critical parts of our application (the rendering loop can be considered as such), we would like to reuse them as many times as possible. Creating and destroying resources may be expensive and time consuming, so doing this every frame may not be the best choice. There are cases in which we probably can get away with that creation/destruction sequence, but if we can avoid this, especially without complicating our code, we should try.
Usually, we cannot modify resources when they are being used during the rendering process; we cannot change the command buffer while the hardware is reading any commands recorded in it. We cannot reuse semaphores if we don't know whether they were already unsignaled by the operations that waited on them. We can only modify resources when we are sure that the hardware doesn't need them anymore. In order to check whether processing of selected commands is already finished, we need to use fences.
Usually we'd like to reuse the whole set of above resources to prepare more frames of animation, re-recording the command buffer and reusing both semaphores. We don't want to destroy them and create their counterparts for each frame. But even if we wanted to, we cannot destroy resources until they are not used anymore. So the fence is still necessary. This gives us the minimal set of resources that are always required to render a single frame of animation:
- At least one command buffer. This buffer is required to record and submit rendering commands to the graphics hardware.
- Image available (image acquired) semaphore. This semaphore gets signaled by a presentation engine and is used to synchronize rendering with swap chain image acquisition.
- Rendering finished (ready to present) semaphore. This semaphore gets signaled when processing of the command buffer is finished and is used to synchronize presentation with the rendering process.
- Fence. A fence indicates when the rendering of a whole frame is finished and informs our application when it can reuse resources from a given frame.
Now we know that at least four Vulkan resources are needed to prepare and render a single frame. Of course, we can use more resources—this list is not closed. We often need an image that acts as a depth attachment (used for depth test) and we may want to use another one while the previous one is still in use, so it may also be a part of the frame resources set. We can also add a framebuffer, used for rendering. Each frame renders to a different swap chain image (we don't know which image will be provided by the presentation engine), and we need to create a framebuffer from that image. So, making a framebuffer a part of frame resources may also simplify our code and make it easier to maintain.
What resources are needed depends on the type of operations we want to perform. The above four resources—two semaphores, a command buffer, and a fence—are the absolute minimum required to manage the frame rendering process.
The Problem
And now the question arises—how many sets of frame resources are needed to prepare and display frames on screen efficiently? Intuition says one set may not be enough. Why? Imagine we acquire an image, record a command buffer, submit it, and then present an image. These operations are synchronized internally with semaphores. Now we want to start preparing another frame of animation, but we can't do that until command buffer processing is complete, and so have to wait until the fence is signaled. The more complex the submitted commands are, the longer we need to wait (because the GPU needs more time to process them). Only after rendering is finished can we start preparing the command buffer for another frame. During these preparations, the GPU sits in an idle state, waiting until new commands are submitted. This makes both the CPU and the GPU operate inefficiently, with a considerable amount of time spent idle.
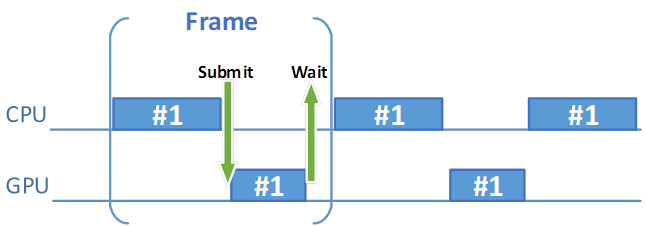
Figure 1. Gaps indicate idle states for the GPU and CPU
What should we do to avoid wasting time? We need another set of resources that we can use to prepare another frame of animation.

Figure 2. Reducing idle states improves efficiency
We prepare the first frame and submit it. Then, immediately, we can start preparing another frame because we have another set of frame resources, so we don't need to wait until the processing of commands from the first frame is finished. Most likely, by the time we finish preparing the second frame, the first frame should already be fully rendered (unless we are GPU-bound).
Then, in the next frame… right, what next? Should we wait until the first frame is not used anymore and reuse resources from the first frame? Or should we have a third set of frame resources? How many frame resources do we need? The sample program should give us an answer.
The Sample Program
The sample program created for this article displays a simple scene with multiple textured quads. Each quad consists of 3,200 triangles (easily adjustable from the code), so despite the fact that they look simple, the scene is quite vertex-heavy. This is done on purpose so we can easily adjust the scene's complexity without affecting command buffer generation time. Initially we have 100 quads, which give us 320,000 triangles, but we can change the number of quads. Apart from that, the sample program allows us to experiment with answers to the question of how the number of sets of frame resources impacts rendering performance. We can also define the time that the CPU spends on additional calculations.
Figure 3. The sample program contains multiple textured quads, each with 3,200 triangles
The most general structure of the rendering loop of the sample program looks like this:
- Waiting on a fence for the next used set of frame resources.
- Acquiring a swap chain image.
- Performing pre-submit calculations (in fact it's only a simulation of work that influences recording of a current frame's command buffer).
- Recording a command buffer and submitting it.
- Performing other calculations (here it simulates work that is performed after submission).
- Drawing a GUI. This signals the fence from a given set of frame resources.
- Presenting the swap chain image.
The parameters
Here are the parameters exposed by the sample program:
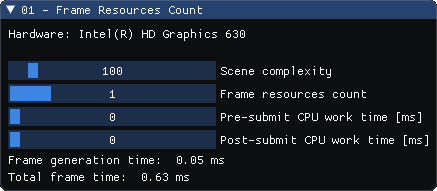
Figure 4. Parameters exposed by the sample program
- Hardware: The name of the graphics hardware on which the application is executed.
- Scene complexity: Adjusts the number of quads displayed on the screen. This parameter allows us to change the number of vertices the GPU has to process each frame, so we can increase or decrease the overall performance of our application.
- Frame resources count: Allows us to define how many sets of frame resources are used for rendering.
- Pre-submit CPU work time: A value simulating how much time (in milliseconds) the CPU spends on calculations that affect the currently recorded command buffer (for example, scene-related visibility culling). These calculations are performed before the command buffer is submitted.
- Post-submit CPU work time: This parameter simulates the time (in milliseconds) the CPU spends on calculations not directly related to the current frame of animation (for example, these may be artificial intelligence (AI) calculations, or a time spent on networking, or calculations that influence the next frame of animation). These calculations are performed after the command buffer submission but before presentation.
- Frame generation time: The time it takes to generate data for a frame. It includes command buffer recording and submission time, and both scene and AI calculations.
- Total frame time: The total time required to prepare a single frame of animation—from the very beginning, just before we wait for a fence to the end, after a swap chain image has been presented.
The experiments
What can we do with the sample program and how should we interpret all the displayed values? To simplify things a bit, let's first adjust the performance of the application by changing the scene complexity parameter. We should change it until we get a reasonable, game-like performance of 60 fps. This means that the frame generation (CPU) and rendering (GPU) together take about 16 milliseconds (ms), as indicated by the total frame time value. However, as seen in the frame generation time parameter, actual frame preparations take very little time. Most of the time is spent waiting on a fence. What happens when we increase the number of frame resources? Not too much (unless we are executing the application on a computer with a very, very slow CPU). We may see a slight increase in performance, but it's not too significant. Why is that? Because the initial command buffer generation takes very little time. This confirms that we are GPU-bound.
In real-life applications, command buffer generation takes much longer. We may need to check which objects are visible, or we may perform physics calculations; perhaps some background data streaming also takes place. This is where the pre-submit CPU work time parameter can help us. By increasing this parameter, we can simulate an increased CPU workload. Our frame generation (rendering) time takes 16 ms, more or less, so we can increase the scene calculations time parameter to something like 14–15 ms (so as to not take longer than it takes for the GPU to render the whole scene). What happens when we still use only one set of frame resources? Performance of our application drops significantly. The performance drops because we increased the time between successive command buffer submissions and thus we increased the time the GPU waits for commands. Initially we have very short frame generation (command buffer recording) times, which look more or less like this:

Figure 5. Short command buffer generation times
After we increase the value of the pre-submit CPU work time parameter, we have more time spent on idle waiting (notice the much bigger gaps in the GPU processing timeline):
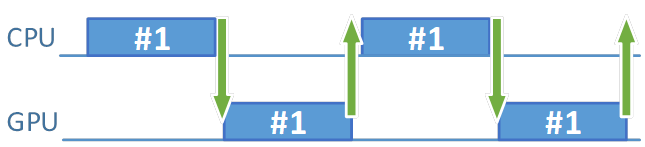
Figure 6. Increased command buffer generation time (simulates a bigger CPU workload)
Now, increase the value of the frame resources count parameter from 1 to 2. What happens? Performance of our application goes back to the initial value of 60 fps. We perform more operations on the CPU (they still take more or less 14—15 ms), our application can now do more things, with performance being unaffected. Because we now fill in the missing holes, we spend the entire time much more efficiently.
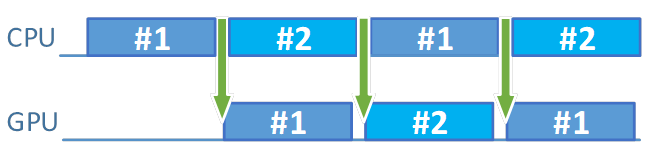
Figure 7. With the frame resource count increased there is far less idle time
What happens if we increase the value of the pre-submit CPU work time parameter even more, beyond 16 ms? We lose the performance, as now we are CPU-bound.
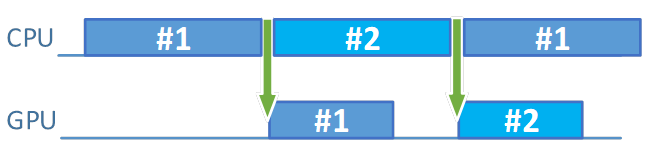
Figure 8. Increasing the pre-submit CPU work time causes the CPU to become the roadblock
Even if we increase the number of sets of frame resources, it won't help us. If we can't feed the GPU with commands, if we can't acquire and present images faster, we are blocked by the CPU. In the above image, we don't even have to wait for the fence (but formally we still need to check its state). This is because before we finish recording the command buffer from the second set of frame resources, the GPU has already finished processing the command buffer from the first set. In such a case, we can only simplify calculations performed by the CPU. What if we don't want to? Then we need a faster CPU.
More sets of frame resources minimize the time both the CPU and the GPU spend on waiting. If we cannot use that time optimally, we won't increase the overall performance of our application.
There is another parameter we can adjust: the post-submit CPU work time. To investigate this parameter, reset all parameters to their initial values, with frame resources count set to 1 and both CPU work times set to 0. Again, set the scene complexity parameter so the scene is rendered with 60 fps. Now increase the post-submit CPU work time parameter to the value of 14–15 ms. What happens now? Nothing! We still render with more or less the same performance. How is that possible? Previously, when we increased the value of the pre-submit CPU work time parameter, performance dropped. So why doesn't it drop now? Pre-submit CPU work time simulates calculations performed before the submission. The post-submit CPU work time parameter simulates calculations performed after the submission. Previously, the time after submission was mostly spent on waiting for the fence. In general, it was wasted. Now we spend it on something more constructive.
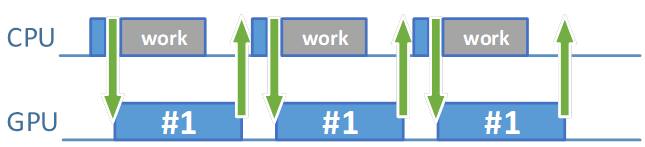
Figure 9. Increasing the post-submit CPU work time parameter has little effect on performance
Of course, if we increase the post-submit CPU work time too much, we will again be CPU-bound and our performance will drop.
The Conclusion
So, what should we do? Do we really need more sets of frame resources? Or should we design our application so it performs calculations in appropriate times?
Having two sets of frame resources is a must. Increasing the number of frame resources to three doesn't give us much more performance (if any at all).
I can imagine situations in which the CPU workload isn't evenly distributed across all frames. Some frames can be generated faster, while it may take more time to prepare data for other frames. Or, in other words, we are close to balancing CPU and GPU work. In such situations, having three sets of frame resources may make the frame rate more stable, with an additional set of frame resources compensating for changing frame generation times (to confirm this, another sample program may be needed). Current tests show that, when we have a stable frame generation and rendering time, two sets of frame resources should suffice.
Since balancing CPU and GPU processing times is difficult, the recommendation is to use three sets of frame resources.
Don't confuse the number of frame resources with the number of swap chain images; the two don't need to be connected. It may be a design choice to have the same number of frame resources as there are swap chain images, but in general, we don't need to connect them. Even with the same creation parameters, the number of images created for a given swap chain may be different on different drivers. During swap chain creation, we specify the minimal number of required images, but implementations (drivers) may create more. So, if we connect the number of frame resources with the number of swap chain images, we may end up with our application behaving differently on various platforms, with higher memory usage being especially noticeable.
Consider the time that the CPU spends on command buffer recording and other calculations. In general, we should try to balance the time it takes for the CPU to prepare frame data and for the GPU to process the data. If the GPU is quick enough and renders the scene much faster than the CPU generates data, we are clearly CPU-bound, and we don't utilize the full potential of the graphics hardware. On the other hand, if the GPU is busy all the time and the CPU easily generates data for rendering, then we are GPU-bound. In this situation it would be hard (if not impossible) to squeeze more performance out of the GPU, but we can spend additional time for such things as more precise physics, or AI calculations. Or, if we are targeting mobile devices, we can leave the CPU workload low to decrease power usage.
What about the moment in which CPU-side calculations are performed? The sample program clearly shows that this is quite important. With a smartly managed CPU workload, we can utilize the GPU's potential while still performing enough calculations on the CPU. But in real life it may be hard to design our application in such a way—especially when we are creating games with tasks such as networking, sound management, streaming data, or synchronizing multiple threads that perform work in the background. It may be hard to plan precisely when these operations occur. With a single set of frame resources, slight changes in frame generation times become noticeable, and framerates stop being smooth. Besides, the sole command buffer recording probably takes much longer than in the sample program. Having at least two sets of frame resources allows us to circumvent these problems, and having three sets of frame resources allows us to further smooth the framerate.
This may also be an interesting debugging tool—if we decrease the number of sets of frame resources, we can check how this change impacts the performance of our application. If it doesn't drop considerably, this may indicate that we are underutilizing the CPU's processing power, and so still have free time to spare.